罗列了100个go开发中容易犯的错误、如何避免这些错误并深入分析其背后的原理,包括一些常见的错误,比如rang loop、defer使用问题,也有一些优化建议,比如减少内存申请次数、理解内存对齐、理解CPU缓存 cache line原理等等,也有一些是凑数的诸如项目结构代码结构之类的。新手老司机都适宜,总体来说非常具有实践意义的一本小书。
第二章 Code and project organizatiion
1. Unintended variable shadowing
当函数返回多个变量时,语句块内通过:=赋值的变量容易把外部的全局同名变量shadow掉。比如
1
2
3
4
5
6
7
var client * http. Client
if xxx {[]()
client, err := foo()
} else {
client, err := bar()
}
// use client
shadow的问题可以通过golangci-lint来发现规避。
2. Unnecessary nested code
没必要的嵌套主要是指我们在if else 分支的时候有时候可以提前返回,而不是一直深度嵌套下去,这样不好维护。如
1
2
3
4
5
6
7
8
9
10
11
12
13
func foo() {
if xxx {
if yyy {
fxxx()
} else {
bbb
return
}
} else {
aaa
return
}
}
上面的代码修改成下面的样子只有一层嵌套对于后续的维护会清晰很多,有时候也可以用continue来代替return。总之就是提前返回
1
2
3
4
5
6
7
8
9
10
11
func foo() {
if ! xxx {
aaa
return
}
if ! yyy {
bbb
return
}
fxxx()
}
作者在书中放了一张图,让符合预期的代码尽量靠前对齐
3. Misusing init functions
我们知道,在go里面,init函数和全局变量是按照package import的顺序来执行的。如果滥用init的话可能会导致一些预期外的bug。
建议init一般只做一些诸如DB Driver初始化之类的。
4. Overusing getters and setters
这应该是C++/Java之类面向对象语言带来的习惯,但是在go里面其实不怎么使用getter和setter,在必要的场景直接用全局变量即可。
5. interface pollution

概念
interface 在开发中给我们带了极大的便利,比如io.Reader和io.Writer这两个interface,里面分别定义了Read和Write,不管Data source和Target是什么只要实现这两个接口就可以和上图意义读写字符串。
什么时候用interface
当然interface虽然很强大也不可滥用,作者建议在以下三种情况下去使用interface
1. 有共同的行为,比如不管标准输入、从磁盘读数据、还是从网络IO读数据都有Read这个行为。这里其实就是行为的抽象。
2. 解耦,这里是SOLID原则中L里氏替换原则的实现,即通过使用基类来替换子类,达到不依赖实现而依赖抽象的解耦。
3. 限制行为,当我们单测的时候一些外部依赖无法在自动化流程正中执行,这时候可以通过interface来实现一个mock。
interface 滥用
只有我们需要interface的时候才去创建它,而不是觉得以后会需要就创建它。滥用interface会增加代码的复杂度,增加一些没必要的层级。
Don’t design with interface, discover them. – Rob pike
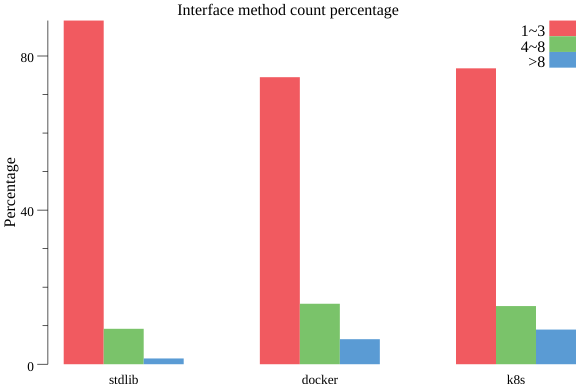
作者引用了一张图,interface中包含方法的个数占比,可以看到绝大部分都是1-3个。
6. interface on the producer side
两种模式后
生产者模式,接口和实现放在一个包里
消费者模式,接口和使用者放在一个包里
7. returning interface
Be conservative in what you do, be liberal in what you accept from others.自己做的时候要谨慎,接受别人的时候开放。
对于函数返回值,尽量返回结构体而不是接口。
对于参数,可以接受接口。
8. any says nothing
即interface{}的使用要谨慎,会使代码失去可读性。
9. Be confused about when to use generics
1.18 带来了范性,但也不能滥用。
推荐场景
数据结构,比如链表、二叉树等等数据结构的
处理任意类型的slice、map、channel的函数
所有类型在实现接口方法时都要做类似的实现逻辑,比如sort函数的Len/Less/Sort 函数
不推荐使用场景
1
2
3
4
func foo[T io. Writer](w T) {
b := getBytes()
- ,_ = w. Write(b)
}
- 使用范性会使得代码复杂化
10. Not being aware of the possible problems with type embedding
内嵌结构体会把父结构体的所有方法暴露,比如我们自定义一个结构体
1
2
3
type Biz struct {
sync.Mutex
}
在上面的结构体中实际上mutex的Lock()和Unlock()方法都暴露出来了,Biz的对象也可以直接用。和其他面向对象语言还是不一样的。
不能用面向对象语言继承的思路来理解go结构体的内嵌。
11. Not using the functional options pattern
主要是针对Newxxx函数传参的问题,建议使用option。可以参考众多标准库或者开源代码的option使用。
12. Project misorganization
这个是项目文件目录结构,其实是一条凑数的,文件结构看公司和个人习惯,只要团队内统一就OK。
13. Creating utility packages
不建议使用util, common, base这样的包,因为这些命名是不符合go的编程哲学,这种属于无意义的包命名,通过名字看不出这个包的功能。
其实个人感觉是有一定道理的,common是个筐,啥都往里装,时间长了必定乱成一团。但对于业务代码,很难做到不设置一个这样的万能框。所以仁者见仁智者见智。
14. Ignoring package name collisions
包命名冲突的问题,也是凑数,现代IDE会帮忙解决这个问题。
15. Missing code documentation
完善代码文档,实际工作中貌似并没有使用过go docs,忽略。
16. Not using linters
第三章 Data Types
17. Creating confusion with octal literals (八进制)
字面数字0或者0o开头表示八进制
同样的道理
二进制以0b或者0B开头,比如0b001
16进制以0x或者0X开头,比如0xFF
虚数以i结尾,比如3i,这个一般工作用不到吧?
go中支持在数字中间加_提高可读性,比如100_000_000,类似逗号提高数字可读性。
18. Neglecting integer overflows
注意整数溢出,go中提供了math.Maxxxx如math.MaxInt这样的最大数定义,如果超出则会溢出。在代码中有必要需要进行判断。
如果有处理大数需求,可以用math/big这个package。
19. Not understanding floating points
float32 使用最高位表示符号位,阶码8位,尾数23位。float64则是阶码11位,尾数52位,由于存储精度有限,无法存储完全准确的值,所以在使用时要注意。
使用==比较两个浮点数时,只要能接受它们的偏差范围就可以。testify 提供了InDalte函数来断言两个浮点类型的数字。
为了提高精确率,在加减操作时,应该把接近数量级的数进行分组操作。书中提供了一段代码如下,f2的精确率会更高
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
func f1(n int ) float64
{
result := 10 _000
for i := 0 ; i < n; i++
{
result += 1.0001
}
return result
}
func f2(n int ) float64
{
result := 0
for i := 0 ; i < n; i++
{
result += 1.0001
}
return result + 10 _000
}
如果要加减乘除混合计算,先执行乘除可以提高精确率。
20. Not understanding slice length and capacity
slice 的基本原理,看看slice的源码就知道了。
slice扩增的时候,当元素小于 1024 时每次扩增 1 倍;之后每次扩增 1/4
21. Inefficient slice initialization
分析几种slice 初始化的效率,最好使用make并指定需要的length或capacity
22. Being confused about nil vs. empty slices
1
2
3
4
var s []string // s为empty同时也是nil
s := []string{nil} // 同上
s := []string{} // s为empty,但不为 nil
s := make([]string, 0 ) // 同上
nil 和 empty 的区别是 nil slice不占用空间,empty的slice只是length为0
上面四种风格最推崇第四种,除非要声明及初始化一些元素,否则第三种是不推荐的。前两种则需要nil slice的时候才用
23. Not properly checking if a slice is empty
对slice的判断使用if len(s) == 0 而不是 if s == nil
nil的slice len()也是0
map也同样的道理
24. Not making slice copies correctly
需要拷贝slice时使用copy函数,需要注意的是copy函数第一个参数是dst 第二个参数是src。
传进去的的dst slice不能为nil。
25. Unexpected side effects using slice append
如果两个slice共享底层数组,对其中一个进行append可能会影响到另一个。
因此如果需要修改,可以使用copy进行深拷贝。或者使用 full slice expression: s[low:high:max],这样就限制了切片的cap
26 Slices and memory leaks
演示了几个slice造成内存泄漏的场景
泄漏capacity
1
2
3
4
5
6
7
8
9
10
11
func consumeMessages() {
for {
msg := receiveMessage()
// Do something with msg
storeMessageType(getMessageType(msg))
}
}
func getMessageType(msg []byte) []byte {
return msg[:5 ]
}
receiveMessage() 返回了数量 1000 的 msg 切片回来,由于 slice 后的数组和 GC 机制,getMessageType 取前 5 个元素的操作,剩下的995元素的内存暂时无法回收。会导致潜在的内存泄漏问题。如果要使用,可以使用copy来把需要的几个元素深拷贝出来。
1
2
3
4
5
func getMessageType(msg []byte) []byte {
msgType := make([]byte, 5 )
copy(msgType, msg)
return msgType
}
因为msgType的capacity只有5,所以只会copy5个字节出来。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
type Foo struct {
v []byte
}
func main() {
foos := make([]Foo, 1 _000)
printAlloc()
for i := 0 ; i < len(foos); i++ {
foos[i] = Foo{
v: make([]byte, 1024 * 1024 ),
}
}
printAlloc()
two := keepFirstTwoElementsOnly(foos)
runtime. GC()
printAlloc()
runtime. KeepAlive(two)
}
func keepFirstTwoElementsOnly(foos []Foo) []Foo {
return foos[:2 ]
}
这段代码中即使使用切片将foos只保留两位,所占用的内存也是不会变的,如果元素是指针或者struct,GC不会回收的。可以用两种方法来避免这个问题。
1
2
3
4
5
func keepFirstTwoElementsOnly(foos []Foo) []Foo {
res := make([]Foo, 2 )
copy(res, foos)
return res
}
采用copy,因为只copy前两个元素,GC知道其他998个元素是不需要了可以回收。
另一种方法则是手动将其余998个元素设置为nil
1
2
3
4
5
6
func keepFirstTwoElementsOnly(foos []Foo) []Foo {
for i := 2 ; i < len(foos); i++ {
foos[i]. v = nil
}
return foos[:2 ]
}
27. Inefficient map initialization
根据map的实现原理,当map容量不足时会触发扩容,而频繁扩容导致数据迁移会造成效率降低。扩容时机有两个
装载因子超过阈值,源码里定义的阈值是 6.5。loadFactor := count / (2^B) count 就是 map 的元素个数,2^B 表示 bucket 数量。
overflow 的 bucket 数量过多:当 B 小于 15,也就是 bucket 总数 2^B 小于 2^15 时,如果 overflow 的 bucket 数量超过 2^B;当 B >= 15,也就是 bucket 总数 2^B 大于等于 2^15,如果 overflow 的 bucket 数量超过 2^15。
因此,map也和slice一样,尽量在初始化的时候提供map的长度,避免扩容操作。
28. Maps and memory leaks
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
n := 1_000_000
m := make(map[int][128]byte)
printAlloc()
for i := 0; i < n; i++ {
m[i] = randBytes()
}
printAlloc()
for i := 0; i < n; i++ {
delete(m, i)
}
runtime.GC()
printAlloc()
runtime.KeepAlive(m)
// 运行结果
// 0 M
// 461 M
// 293 M
上面这段代码将map中的元素挨个delete掉内存并不会恢复到0,原因是map中的bucket的数量不会缩减。即是时将元素删除也不会影响bucket的数量只不过是将bucket中的slot清零。而降低的内存应该是bmap中overflow指向的bucket,map[int][128]byte中的数组[128]byte空值就占用128字节。
解决办法有两个
第一个方法是不断将map copy到一个新的map,这样如果数据变少了,老map就释放了,但这显然不是一个优雅的操作。
另一个方法是将map中的value修改为指针,减少空value占用的空间
另外书中提到一个tips:如果key或value超过128字节,Go不会将其直接存储在映射存储桶中。相反,Go存储一个指针来引用这个key或value。
29. Comparing values incorrectly
slice和map是数据不可比较类型,== != 等比较操作是无效的。
如果一个struct中有不可比较类型的元素,那这个struct也是不可比较类型了。
对于不可比较类型,可以使用reflect.DeepEqual来比较,但是由于性能不好,很多场景建议自己实现比较函数,比如for循环比较slice中的每个元素。
标准库中也有一些比较函数,比如bytes.Compare
第四章 Control structures
30. Ignoring the fact that elements are copied in range loops
range loops里面的value是一个副本 —- 这很重要。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
type account struct {
balance float32
}
accounts := []account{
{balance: 100.},
{balance: 200.},
{balance: 300.},
}
for _, a := range accounts {
a.balance += 1000
}
// 结果是 [{100} {200} {300}]
原因是 a 是一个副本。
可以通过下面两种方式来解决这个问题,其实都是采用index来操作slice本身。
1
2
3
4
5
6
7
for i := range accounts {
accounts[i].balance += 1000
}
for i := 0; i < len(accounts); i++ {
accounts[i].balance += 1000
}
1
2
3
4
5
6
7
8
accounts := []*account{
{balance: 100.},
{balance: 200.},
{balance: 300.},
}
for _, a := range accounts {
a.balance += 1000
}
31. Ignoring how arguments are evaluated in range loops
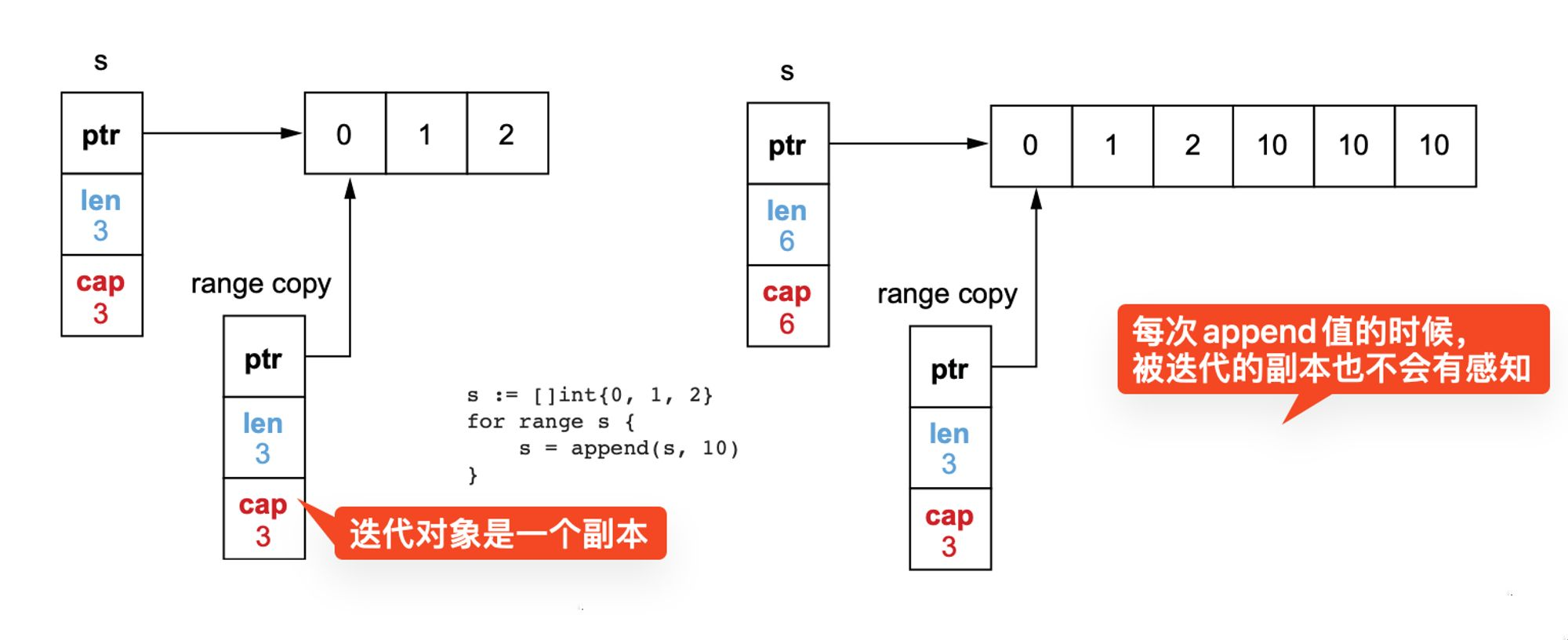
for i, v := range exp range loop 的对象是一个表达式,这个表达式可以是 string, slice, map等,当执行循环的时候,exp只会被计算一次,对原始迭代值进行拷贝生成一个副本。对比下面两段代码哪个会有死循环
1
2
3
4
5
6
7
8
9
10
11
s := []int{0, 1, 2}
for range s
{
s = append(s, 10)
}
for i := 0; i < len(s); i++
{
s = append(s, 10)
}
很显然第二个for循环会是死循环,但第一个并不会,执行3次就结束了,因为迭代的是一个副本。
书中还举了一个channel的例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
ch1 := make(chan int, 3)
go func() {
ch1 <- 0
ch1 <- 1
ch1 <- 2
close(ch1)
}()
ch2 := make(chan int, 3)
go func() {
ch2 <- 10
ch2 <- 11
ch2 <- 12
close(ch2)
}()
ch := ch1
for v := range ch {
fmt.Println(v)
}
// 输出 0 1 2, 因为ch是ch1的一个副本
32. Ignoring the impact of using pointer elements in range loops
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
type Customer struct {
ID string
Balance float64
}
type Store struct {
m map[string]* Customer
}
func main() {
s := Store{
m: make(map[string]* Customer),
}
s. storeCustomers([]Customer{
{ID: "1" , Balance: 10 },
{ID: "2" , Balance: - 10 },
{ID: "3" , Balance: 0 },
})
print (s. m)
}
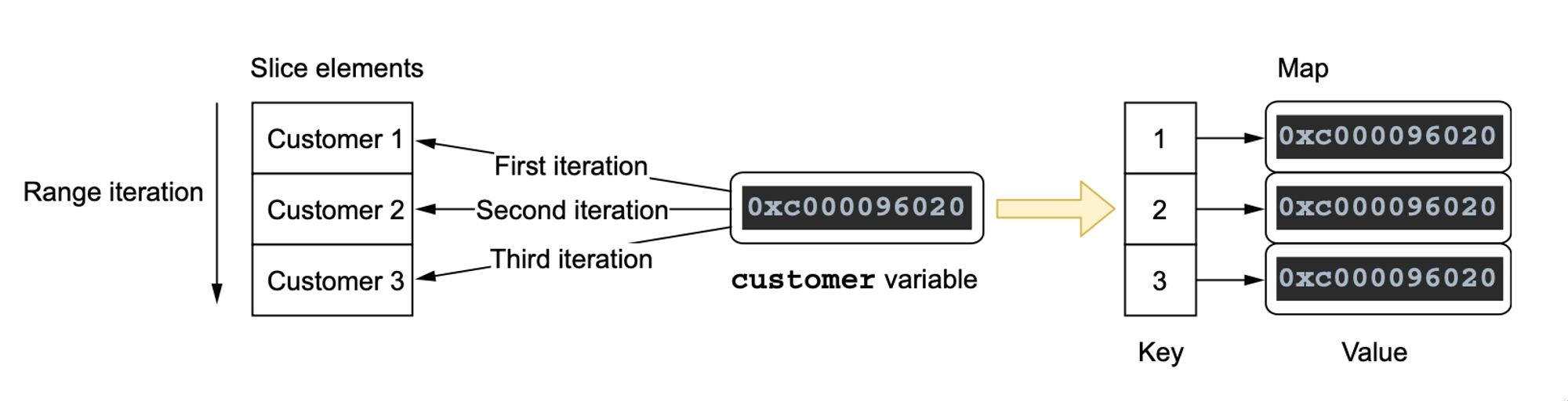
// 这里的结果会是
// key= 1 , value=& main. Customer{ID:"3" , Balance:0 }
// key= 2 , value=& main. Customer{ID:"3" , Balance:0 }
// key= 3 , value=& main. Customer{ID:"3" , Balance:0 }”
// 问题在于在这个循环中每次迭代的时候 customer 都是同一个对象,只是 customer 的值会不断被新的值覆盖
func (s * Store) storeCustomers(customers []Customer) {
for _, customer := range customers {
s. m[customer. ID] = & customer
}
}
func print (m map[string]* Customer) {
for k, v := range m {
fmt. Printf("key= %s , value=%#v \n " , k, v)
}
}
问题解析
第一次循环customer 引用了第一个元素,我们存储了一个指向customer结构的指针。
第二次循环customer 引用了第一个元素,我们也存储了一个指向customer结构的指针。
第三次循环customer 引用了第一个元素,我们同样存储了一个指向customer结构的指针。
最后我们存储了同一个指针三次,它最后只想最后一个元素。
解决方案有两个,第一个把每次迭代的值copy到一个新的临时变量
1
2
3
4
5
6
func (s * Store) storeCustomers2(customers []Customer) {
for _, customer := range customers {
current := customer
s. m[current. ID] = & current
}
}
第二个直接引用切片的元素,但这里有风险,如果slice出现扩容的时候,那原本地址还是被引用,可能出现内存泄露
1
2
3
4
5
6
func (s * Store) storeCustomers3(customers []Customer) {
for i := range customers {
customer := & customers[i]
s. m[customer. ID] = customer
}
}
33. Making wrong assumptions during map iterations
map是无序的,如果非要按序输出可以使用第三方库gods ,这个库实现了很多go的数据结构其中包括有序的map,使用tree来实现可以做到有序,而标准库是hashmap。
map在迭代中插入元素可能会带来不可预期的结果,比如插入的元素会被跳过不被迭代到。不能这做。
34. Ignoring how the break statement works
break只能跳出一层循环,尤其是for switch 嵌套使用时。比如下面的代码,break只能跳出switch这一层,如果非要跳出可以用label来控制
1
2
3
4
5
6
7
8
9
for i := 0; i < 5; i++ {
fmt.Printf("%d ", i)
switch i {
default:
case 2:
break
}
}
35. Using defer inside a loop
defer 只会在函数结束的时候执行
下面这段代码在每次循环后并不会执行defer
1
2
3
4
5
6
7
8
9
10
11
12
13
func readFiles(ch <- chan string) error {
for path := range ch {
file, err := os. Open(path)
if err != nil {
return err
}
defer file. Close()
// Do something with file
}
return nil
}
如果想要解决这个问题可以将循环中这段代码抽取出来作为一个函数,或者采用闭包。
1
2
3
4
5
6
7
8
9
10
11
12
13
func readFiles(ch <- chan string) error {
for path := range ch {
err := func () error {
// ...
defer file. Close()
// ...
}()
if err != nil {
return err
}
}
return nil
}
第五章 Strings
36. Not understanding the concept of a rune
go是采用UTF8来编码的,如果要使用Unicode则要用rune
注意len函数返回的是字节长度,而不是rune的长度。一个rune字符可能占1-4个字节。
37. Inaccurate string iteration
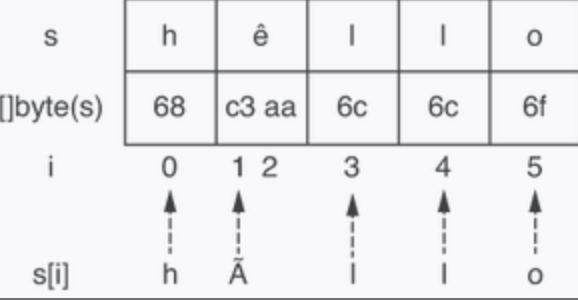
当string中不全是utf8时,采用index迭代会按照字节输出。像下面这段代码第二个字符和len长度都不符合预期。
1
2
3
4
5
6
7
8
9
10
11
12
13
s := "hêllo"
for i := range s {
fmt.Printf("position %d: %c\n", i, s[i])
}
fmt.Printf("len=%d\n", len(s))
// 输出
// position 0: h
// position 1: Ã
// position 3: l
// position 4: l
// position 5: o
// len=6”
可以转成[]rune, 不过转rune会有内存copy操作,而且时间时间复杂度是O(n)。采用range loop来迭代,如下图也是正确的。
1
2
3
4
s := "hêllo"
for i, r := range s {
fmt.Printf("position %d: %c\n", i, r)
}
fmt.Println(utf8.RuneCountInString(s)) // 5 这个方法可以计算string中rune的个数
38. Misusing trim functions
只是Trim的使用
TrimRight/TrimLeft removes the trailing/leading runes in a set.
TrimSuffix/TrimPrefix removes a given suffix/prefix.
39. Under-optimized string concatenation
1
2
3
4
5
6
7
func concat(values []string) string {
s := ""
for _, value := range values {
s += value
}
return s
}
1
2
3
4
5
6
7
func concat(values []string) string {
sb := strings. Builder{}
for _, value := range values {
_, _ = sb. WriteString(value)
}
return sb. String()
}
1
2
3
4
5
6
7
8
9
10
11
12
13
func concat(values []string) string {
total := 0
for i := 0 ; i < len(values); i++ {
total += len(values[i])
}
sb := strings. Builder{}
sb. Grow(total)
for _, value := range values {
_, _ = sb. WriteString(value)
}
return sb. String()
}
性能对比
40. Useless string conversions
bytes 包支持很多和strings包类似的方法,如果有直接使用的方法要避免将[]byte转化为string来操作,比如bytes.TrimSpace 方法。
41. Substrings and memory leaks
和26条slice类似,子字符串引用一个较长父字符串的部分内容,会导致父字符串不能被GC,造成内存泄漏。
第六章 Function and methods
42. Not knowing which type of receiver to use
1
2
3
4
5
6
7
8
9
10
11
type customer struct {
balance float64
}
func (c customer)Add(v float64) {
c. balance += v
}
func (c * customer)Add(v float64) {
c. balance += v
}
43. Never using named result parameters
接口定义的函数使用命名返回参数,可以提升可读性,尤其是返回多个同类型结果时。但如果函数太长也不太合适,一来可读性也不一定高,另外也容易出现变量被shadow。
44. Unintended side effects with named result parameters
就是上面说的命名结果容易被shadow或者忘记赋值直接返回。特别是err。
45. Returning a nil receiver
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
type MultiError struct {
errs []string
}
func (m * MultiError) Add(err error) {
m. errs = append(m. errs, err. Error())
}
func (m * MultiError) Error() string {
return strings. Join(m. errs, ";" )
}
func (c Customer) validate() error {
var m * MultiError
if c. Age < 0 {
m = & MultiError{}
m. Add(errors. New("age is negative" ))
}
if c. Name == "" {
if m == nil {
m = & MultiError{}
}
m. Add(errors. New("name is nil" ))
}
return m
}
1
2
3
4
customer := Customer{Age: 33, Name: "John"}
if err := customer.Validate(); err != nil {
log.Fatalf("customer is invalid: %v", err)
}
1
2
3
4
5
6
7
8
9
10
11
12
func countEmptyLinesInFile(filename string) (int , error) {
file, err := os. Open(filename)
if err != nil {
return 0 , err
}
// Handle file closure
scanner := bufio. NewScanner(file)
for scanner. Scan() {
// ...
}
}
这里入参如果是文件名的话这个函数就没什么扩展性,如果输入变成了HTTP或者socket等输入时就不适用了,同时也不方便测试,测试时还得先创建一个文件。更优雅的做法应该是将入参设置为io.Reader
1
2
3
4
5
6
func countEmptyLines(reader io. Reader) (int , error) {
scanner := bufio. NewScanner(reader)
for scanner. Scan() {
// ...
}
}
47. Ignoring how defer arguments and receivers are evaluated
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
const (
StatusSuccess = "success"
StatusErrorFoo = "error_foo"
StatusErrorBar = "error_bar"
)
func f() error {
var status string
defer notify(status)
defer incrementCounter(status)
if err := foo(); err != nil {
status = StatusErrorFoo
return err
}
if err := bar(); err != nil {
status = StatusErrorBar
return err
}
status = StatusSuccess
return nil
}
这里两个defer函数得到的都是空字符串,因为defer在定义的时候会把函数压栈保存,即使在后面赋值也没有用了。
最佳解决方案是采用闭包,总之defer用闭包就对了
1
2
3
4
5
6
7
8
9
func f() error {
var status string
defer func () {
notify(status)
incrementCounter(status)
}()
// The rest of the function is unchanged
}
第七章 Error management
48. Panicking
介绍panic,panic应该尽量少用,最好使用一个函数来处理错误。
49. Ignoring when to wrap an error
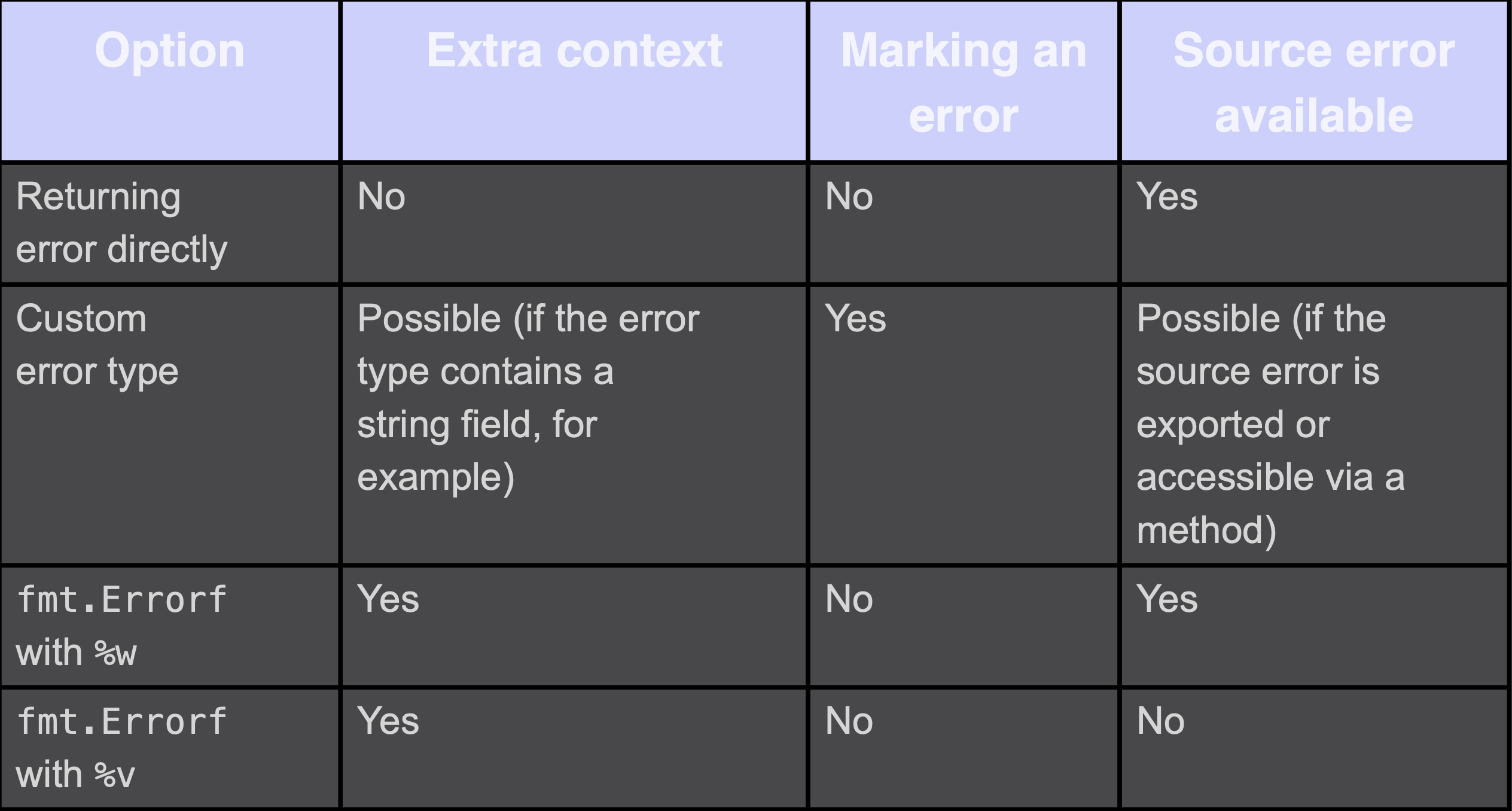
wrap指为一个错误添加额外的上下文和/或将一个错误标记为特定的类型。如果我们需要标记一个错误,我们应该创建一个自定义的错误类型。然而,如果我们只是想添加额外的上下文,可以使用带有%w指令的fmt.Errorf,因为它不需要创建一个新的错误类型。
但是wrap error会产生潜在的耦合,因为它使源错误对调用者可用。如果我们想防止它,我们不应该使用错误包装,而应该使用错误转换,例如,使用fmt.Errorf与%v指令。
50. Checking an error type inaccurately
当使用%w指令或者结构体封装的方式包装一个错误的时候,可以使用 errors.As 递归判断错误类型,errors.As函数需要传递一个目标错误类型的指针。
errors.As 的用法如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
func handler(w http. ResponseWriter, r * http. Request) {
// Get transaction ID
amount, err := getTransactionAmount(transactionID)
if err != nil {
if errors. As(err, & transientError{}) {
http. Error(w, err. Error(),
http. StatusServiceUnavailable)
} else {
http. Error(w, err. Error(),
http. StatusBadRequest)
}
return
}
// Write response
}
51. Checking an error value inaccurately
有时候有一些error实际上是合法的,并不是错误,这种错误叫sentinel errors,比如DB操作的ErrRecordNotFound;这种错误一般是全局定义,以Err开头。
当在业务上层去判断这种错误时,如果直接用== 可能会有问题,因为错误可能被包装。可以用errors.Is来获取这个error的值。
52. Handling an error twice
当调用链很长的时候,多次处理同一个错误,比如对同一个错误在内层和外层都打印日志。
书中建议只对日志处理一次,比如在最外层打印日志,但为了防止上下文丢失,每次返回错误的时候都要wrap包一层,将该环节的上下文带上去。
53. Not handling an error
有时候被调用的函数是会返回error的,但我们调用层不需要去处理,最好注释不处理的原因。
54. Not handling defer errors
defer语句通常用于做收尾工作,有时候在defer中调用的函数会返回错误,如果不处理这些错误就会导致错误信息丢失,造成资源泄露等问题。书中建议,在defer的时候把错误值赋值给返回结果,向上传递错误。
但是如果直接给返回出去的err赋值,可能会覆盖原来的err,因此可以按照下面代码的方式来处理。
1
2
3
4
5
6
7
8
9
10
defer func() {
closeErr := rows.Close()
if err != nil {
if closeErr != nil {
log.Printf("failed to close rows: %v", err)
}
return
}
err = closeErr
}()
第八章 Concurrency: Foundations
55. Mixing up concurrency and parallelism
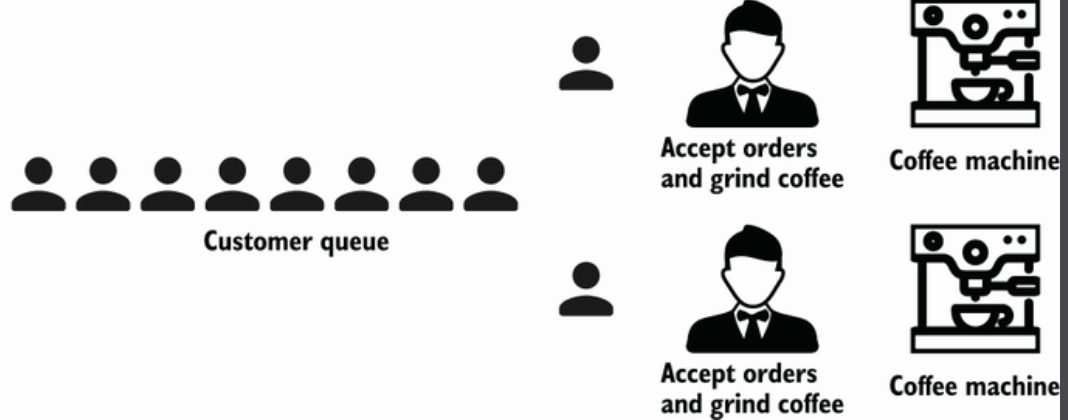
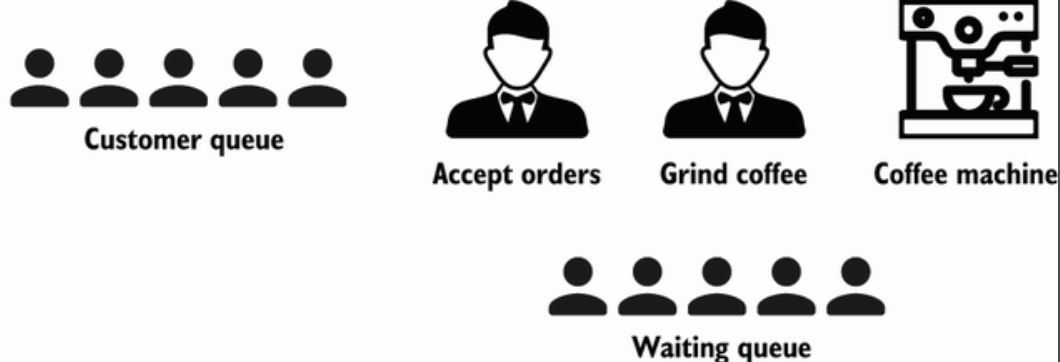
并发和并行的区别,更多解释可以自行搜索,书中用顾客和咖啡机的例子来解释
并行
并发
Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once. —Rob Pike
56. Thinking concurrency is always faster
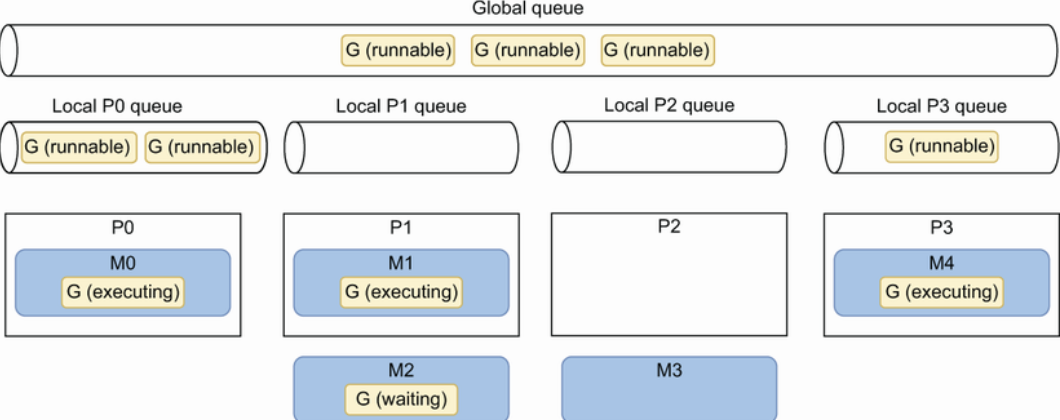
介绍go调度 GMP 实现原理,这方面个人觉得写得最好的资料来自go语言原本
书中强调并发并不一定是快的,通过一个归并排序的例子说明
普通递归版本
1
2
3
4
5
6
7
8
9
10
func sequentialMergesort(s []int ) {
if len(s) <= 1 {
return
}
middle := len(s) / 2
sequentialMergesort(s[:middle])
sequentialMergesort(s[middle:])
merge(s, middle)
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
func parallelMergesortV1(s []int ) {
if len(s) <= 1 {
return
}
middle := len(s) / 2
var wg sync. WaitGroup
wg. Add(2 )
go func () {
defer wg. Done()
parallelMergesortV1(s[:middle])
}()
go func () {
defer wg. Done()
parallelMergesortV1(s[middle:])
}()
wg. Wait()
merge(s, middle)
}
1
2
Benchmark_sequentialMergesort-4 2278993555 ns/op
Benchmark_parallelMergesortV1-4 17525998709 ns/op
主要是需要一直go下去,每个goroutine的负载非常小,得不偿失。
最后书中也给出了一个最优解,当元素小于某个值时用串行,大于某个值时用并行方式。
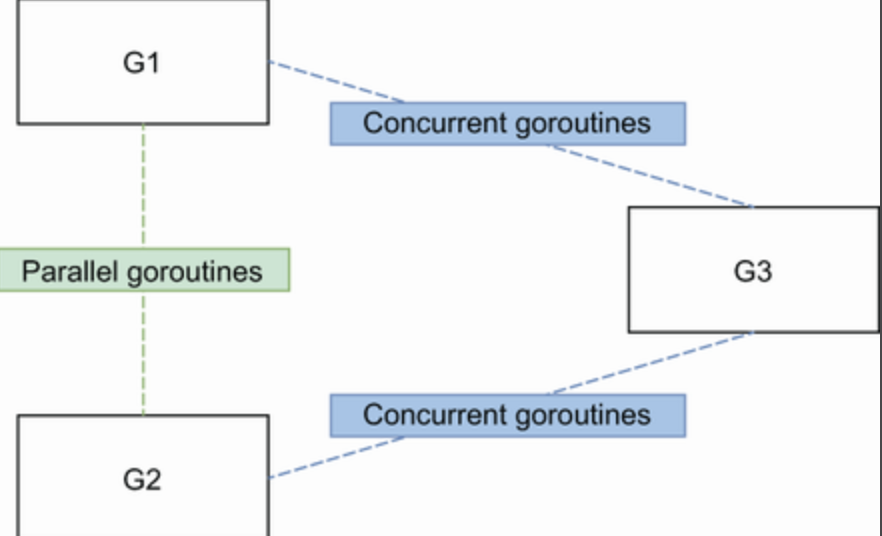
57. Being puzzled about when to use channels or mutexes
并行的goroutine当他们要访问或者改变一个共享变量时得用mutex。比如上面的G1 G2
并发的goroutine需要协调,比如上面G3 要汇总G1 G2 的结果,可以通过channel来向G3发信号。
更多延伸阅读CSP 同步原语与锁
58. Not understanding race problems
数据竞争指的是两个以上goroutine,同时访问一个内存位置,其中至少一个是写。
解决数据竞争
使用atomic包
使用mutex保护临界区
使用channel来传递数据
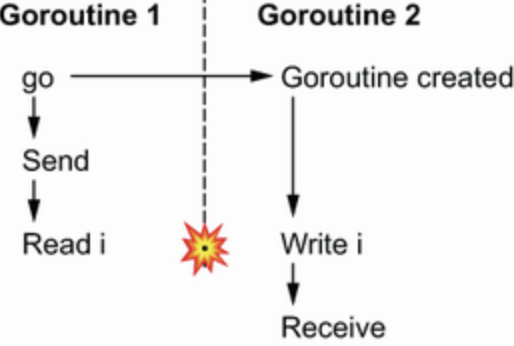
内存一致性模型,延伸阅读 。书中通过一些例子来讲解go的内模型,其中下面两个例子分享buffered channel和unbuffered channel需要注意,其他都是比较简单的例子。
有数据竞争
1
2
3
4
5
6
7
8
i := 0
ch := make(chan struct{}, 1)
go func() {
i = 1
<-ch
}()
ch <- struct{}{}
fmt.Println(i)
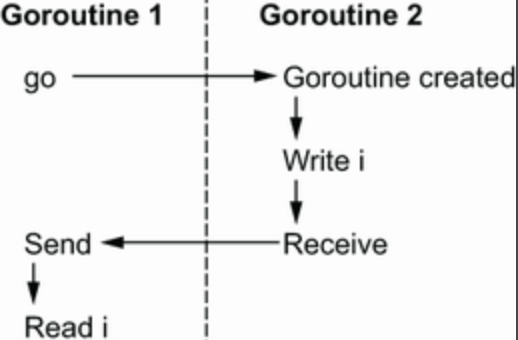
没有数据竞争
1
2
3
4
5
6
7
8
i := 0
ch := make(chan struct{})
go func() {
i = 1
<-ch
}()
ch <- struct{}{}
fmt.Println(i)
59. Not understanding the concurrency impacts of a workload type
为了提高效率,我们经常会使用协程池模式来并发处理,这个池子大小或者说并发数该怎么选择呢。需要根据任务是CPU密集还是IO密集来决定
如果是IO密集型任务,则取决于外部系统,比如DB。
如果是CPU密集型任务,则取决于runtime.GOMAXPROCS,也就是让每个 M都在同时运行。
60. Misunderstanding Go contexts
这条主要是介绍了一下context,官方定义“A Context carries a deadline, a cancellation signal, and other values across API boundaries.”
第九章 Concurrency: Practice
61. Propagating an inappropriate context
1
2
3
4
5
6
7
8
9
10
11
12
13
14
func handler(w http. ResponseWriter, r * http. Request) {
response, err := doSomeTask(r. Context(), r)
if err != nil {
http. Error(w, err. Error(), http. StatusInternalServerError)
return
}
go func () {
err := publish(r. Context(), response)
// Do something with err
}()
writeResponse(response)
}
考虑上面这段代码,如果http在publish执行完成之前返回来,context被cancel,publish可能就失败了。
第个解决方案很简单,将context替换成一个空context err := publish(context.Background(), response)
但如果context带有用信息,则可以选择定制一个custom context 来继承context
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
type detach struct {
ctx context. Context
}
func (d detach) Deadline() (time. Time, bool ) {
return time. Time{}, false
}
func (d detach) Done() <- chan struct{} {
return nil
}
func (d detach) Err() error {
return nil
}
func (d detach) Value(key any) any {
return d. ctx. Value(key)
}
// 使用
err := publish(detach{ctx: r. Context()}, response)
62. Starting a goroutine without knowing when to stop it
goroutine 泄漏指的是goroutine没有得到回收,导致它本身的内存以及一些goroutine中运行的网络连接、DB连接等资源的泄漏。
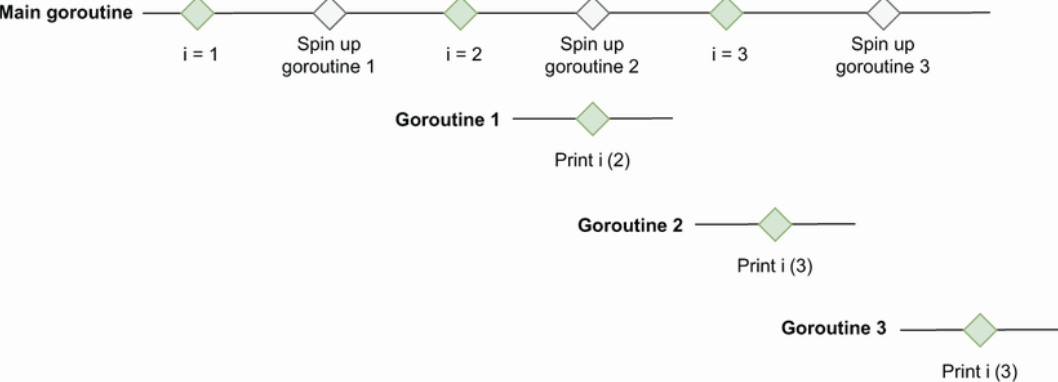
63. Not being careful with goroutines and loop variables
这是一个非常容易犯的错误,本质上还是range loop的问题,参考第30条。
1
2
3
4
5
6
7
s := []int{1, 2, 3}
for _, i := range s {
go func() {
fmt.Print(i)
}()
}
上面的代码得不到预期的1 2 3,而是会得到一个不稳定的输出,比如2 3 3 ,3 3 3 。原因在于闭包是一个函数值,它引用其主体之外的变量:这里是i变量。当一个闭包的goroutine被执行时,它并没有捕捉到goroutine被创建时的值。相反,所有的goroutine都引用了完全相同的变量。当一个goroutine运行时,它打印的是执行fmt.Print时的i的值。因此,自从goroutine启动以来,i可能已经被修改了。
这是对输出2 3 3 结果的一个示意图。
如何解决呢?采用一个临时变量,将i copy一份
1
2
3
4
5
6
for _, i := range s {
val := i
go func() {
fmt.Print(val)
}()
}
1
2
3
4
5
for _, i := range s {
go func(val int) {
fmt.Print(val)
}(i)
}
64. Expecting deterministic behavior using select and channels
这条主要是要说明select中的case执行顺序是随机的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
for {
select {
case v := <-messageCh:
fmt.Println(v)
case <-disconnectCh:
fmt.Println("disconnection, return")
return
}
}
for i := 0; i < 10; i++ {
messageCh <- i
}
disconnectCh <- struct{}{}
这段代码的预期是往messageCh写入10个数,然后关闭。但实际可能打到5就关闭了。原因就是messageCh、disconnectCh 这两个ch是随机执行的。解决方法是再加一层for-select
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
for {
select {
case v := <-messageCh:
fmt.Println(v)
case <-disconnectCh:
for {
select {
case v := <-messageCh:
fmt.Println(v)
default:
fmt.Println("disconnection, return")
return
}
}
}
}
65. Not using notification channels
66. Not using nil channels
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
func merge(ch1, ch2 <- chan int ) <- chan int {
ch := make(chan int , 1 )
go func () {
for {
select {
case v := <- ch1:
ch <- v
case v := <- ch2:
ch <- v
}
}
close(ch)
}()
return ch
}
上面这段merge两个channel的代码,存在一个问题,close(ch) 没有起到效果,当ch1 或者ch2 close掉以后ch依然会持续收到0值。是go对于close的channel依然会receive 0值。
1
2
3
4
5
6
received: 0
received: 0
received: 0
received: 0
received: 0
...
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
func merge(ch1, ch2 <- chan int ) <- chan int {
ch := make(chan int , 1 )
ch1Closed := false
ch2Closed := false
go func () {
for {
select {
case v, open := <- ch1:
if ! open { ❶
ch1Closed = true
break
}
ch <- v
case v, open := <- ch2:
if ! open { ❷
ch2Closed = true
break
}
ch <- v
}
if ch1Closed && ch2Closed { ❸
close(ch)
return
}
}
}()
return ch
}
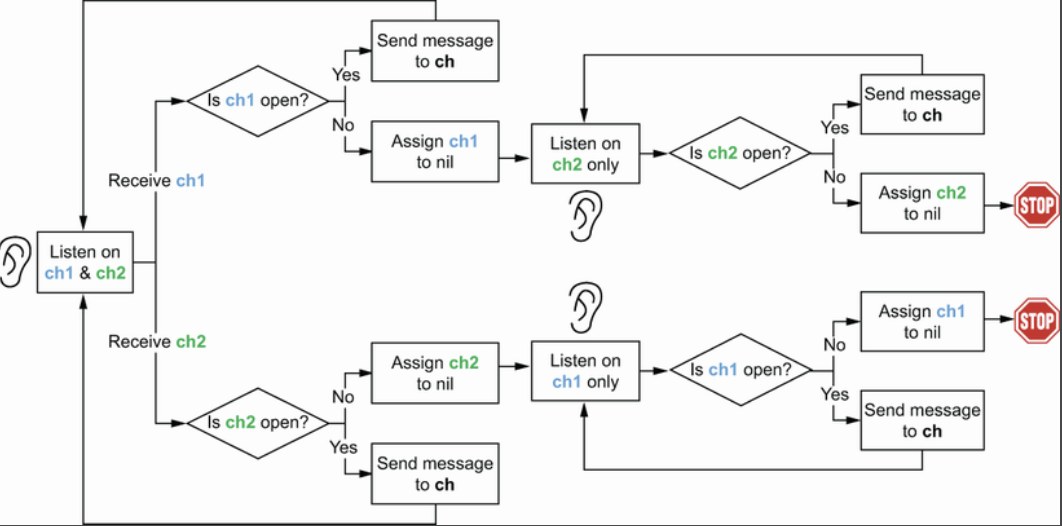
上面这段代码解决了ch无法close的问题,但是还是不够完美,当ch1 或者ch2 任意一个先close,另一个依然会继续循环,浪费CPU资源。可以继续优化,因为接受或者发送nil channel是一个阻塞行为,所以将已经close的channel设置为nil可以阻塞避免CPU白用功。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
func merge(ch1, ch2 <- chan int ) <- chan int {
ch := make(chan int , 1 )
go func () {
for ch1 != nil || ch2 != nil { ❶
select {
case v, open := <- ch1:
if ! open {
ch1 = nil ❷
break
}
ch <- v
case v, open := <- ch2:
if ! open {
ch2 = nil ❸
break
}
ch <- v
}
}
close(ch)
}()
return ch
}
最终的一个示意图
67. Being puzzled about channel size
无buffer的channel 没有任何空间,ch1 := make(chan int) / ch1 := make(chan int, 0), sender会一直阻塞直到receiver把数据读出。一般用于同步场景。
相反有buffer的channel 长度必须大于等于1,当channel满了以后sender会一直阻塞直到receiver把数据读出。一般用于消息传递、控制goroutine数量协程池等等。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
type Customer struct {
mutex sync. RWMutex ❶
id string
age int
}
func (c * Customer) UpdateAge(age int ) error {
c. mutex. Lock()
defer c. mutex. Unlock()
if age < 0 { ❸
return fmt. Errorf("age should be positive for customer %v" , c)
}
c. age = age
return nil
}
func (c * Customer) String () string {
c. mutex. RLock() ❹
defer c. mutex. RUnlock()
return fmt. Sprintf("id %s , age %d " , c. id, c. age)
}
上面这段代码会带来死锁,因为在age < 0 的时候,对customer 结构体 %v 格式化的时候会调用String函数,因为UpdateAge还没释放,所以String函数就无法获得。
这里要么缩小锁的粒度,要么不使用String函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
func (c * Customer) UpdateAge(age int ) error {
if age < 0 {
return fmt. Errorf("age should be positive for customer %v" , c)
}
c. mutex. Lock() // 将锁粒度变小
defer c. mutex. Unlock()
c. age = age
return nil
}
func (c * Customer) UpdateAge(age int ) error {
c. mutex. Lock()
defer c. mutex. Unlock()
if age < 0 {
return fmt. Errorf("age should be positive for customer id %s " , c. id) // 只对 c. id进行打印就不会使用到String 方法了
}
c. age = age
return nil
}
69. Creating data races with append
1
2
3
4
5
6
7
8
9
10
11
s := make([]int, 1)
go func() {
s1 := append(s, 1)
fmt.Println(s1)
}()
go func() {
s2 := append(s, 1)
fmt.Println(s2)
}()
上面这段代码并不会出现数据竞争,因为s的len和capacity相等,都是1。两个goroutine append的时候都会扩容创建新的底层数组。但如果将s初始化换成s := make([]int, 0, 1) 那就会有数据竞争了。
关于slice和map的数据竞争
当多个goroutine访问同一个index的slice时,如果至少有一个goroutine修改数据,那么是数据竞争,因为它们访问的是同一片内存。无论读写,访问不同的index的slice都不是数据竞争,因为不是同块内存。
当多个goroutine访问一个map至少有一个写入时,无论是否相同的key都是数据竞争,因为map是一个桶的数组,hash算法具有随机性,一次操作可能会涉及到相同的数组index,所以不管会不会数据竞争,race处理都会告警。
70. Using mutexes inaccurately with slices and maps
对map和slice的赋值只是拷贝引用,实际底层都是同一个数据集
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
type Cache struct {
mu sync. RWMutex
balances map[string]float64
}
func (c * Cache) AddBalance(id string, balance float64) {
c. mu. Lock()
c. balances[id] = balance
c. mu. Unlock()
}
func (c * Cache) AverageBalance() float64 {
c. mu. RLock()
balances := c. balances // 问题出在这里, balances只是c. balances只是拷贝引用
c. mu. RUnlock()
sum := 0.
for _, balance := range balances {
sum += balance
}
return sum / float64(len(balances))
}
解决方法是要么在AverageBalance里面放大锁的粒度,要么将c.balances深拷贝。
71. Misusing sync.WaitGroup
1
2
3
4
5
6
7
8
9
10
11
12
13
wg := sync. WaitGroup{}
var v uint64
for i := 0 ; i < 3 ; i++ {
go func () {
wg. Add(1 )
atomic. AddUint64(& v, 1 )
wg. Done()
}()
}
wg. Wait()
fmt. Println(v)
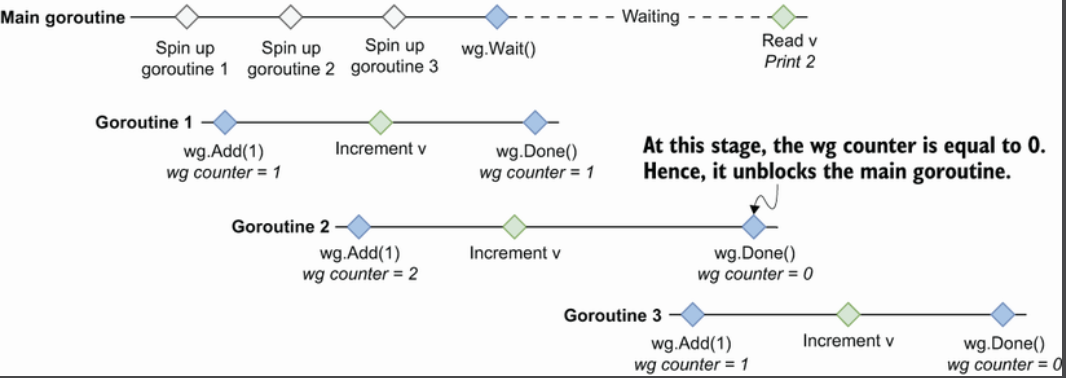
上面这段代码预期是打印3,但实际上会得到0-3中的任意值。问题在于,wg.Add(1)是在新创建的goroutine中调用的,而不是在父goroutine中。因此,不能保证我们在调用wg.Wait()之前已经向waitgroup表明我们要等待三个goroutine。
这是这些协程的执行示意图
解决方法有两个
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// 方案一,直接在父 goroutine中Add 3
wg := sync. WaitGroup{}
var v uint64
wg. Add(3 )
for i := 0 ; i < 3 ; i++ {
go func () {
// ...
}()
}
// 方案二,将 Add放在协程外
wg := sync. WaitGroup{}
var v uint64
for i := 0 ; i < 3 ; i++ {
wg. Add(1 )
go func () {
// ...
}()
}
// ...
72. Forgetting about sync.Cond
Go中可以通过channel来实现信号传递。多个goroutine能够捕捉到的唯一事件是通道关闭,但这只可能发生一次。因此,如果我们反复向多个goroutine发送通知时,sync.Cond是一个解决方案。使用sync.Cond,我们可以广播信号,唤醒所有等待一个条件的goroutine。
73. Not using errgroup
errgroup的用法,可以收集多个goroutine的错误。不过有一个限制函数签名必须是`func() error {}
k8s 提供了一个聚合error的方法 可以参考。
74. Copying a sync type
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
type Counter struct {
mu sync. Mutex
counters map[string]int
}
func NewCounter() Counter { ❶
return Counter{counters: map[string]int {}}
}
// receiver是value类型
func (c Counter) Increment(name string) {
c. mu. Lock() ❷
defer c. mu. Unlock()
c. counters[name]++
}
// 两个 goroutine调用Increment
go func () {
counter. Increment("foo" )
}()
go func () {
counter. Increment("bar" )
}()
上面这段代码依然会出现数据竞争,原因是Increment实现的receiver是值类型,根据前面所说我们知道这种情况每次调用Increment counter都会做一次copy,mutex在copy之后就没有意义了。
sync包里的 Mutex、Cond、Map、RWMutex、Once、Pool、WaitGroup都是不能被拷贝的。
第十章 标准库
75. Providing a wrong time duration
time 包中的函数参数类型一般是time.Duration,不要直接用数字。
76. time.After and memory leaks
一次调用 time.After 会使用大约200字节的内存。但是只有在指定的时间到达的时候才会GC,如果在1小时内,频繁的调用 time.After 会导致内存持续上涨。
77. Common JSON-handling mistakes
Unexpected behavior due to type embedding
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
type Event struct {
ID int
time.Time
}
event := Event{
ID: 1234,
Time: time.Now(),
}
b, err := json.Marshal(event)
if err != nil {
return err
}
fmt.Println(string(b))
在这个例子中,ID字段将不会输出,原因有两个
如错误10中所说,如果一个嵌入式字段类型实现了一个接口,那么包含嵌入式字段的结构也将实现这个接口。
我们可以通过让一个类型实现json.Marshaler接口来改变默认的Marshaling行为。这个接口包含一个单一的 MarshalJSON 函数
解决方法有两个,首先不必说,不适用嵌入式字段,为time指定一个名字 Time time.Time。另一个方法则是为Event实现Marshal方法
1
2
3
4
5
6
7
8
9
10
11
func (e Event) MarshalJSON() ([]byte, error) {
return json. Marshal(
struct {
ID int
Time time. Time
}{
ID: e. ID,
Time: e. Time,
},
)
}
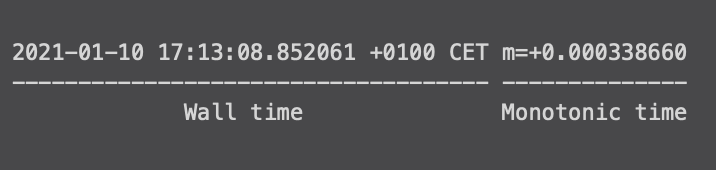
JSON and the monotonic clock
在go中,时间分为墙上时钟和单调时种,墙上时钟指的是当前的时钟,单调时钟则是永远向前的。当我们打印时间时,它同时包含着两种时间
在json处理中,unmarshal会丢失单调时钟。看下面的例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
type Event struct {
Time time. Time
}
t := time. Now()
event1 := Event{
Time: t,
}
b, err := json. Marshal(event1)
if err != nil {
return err
}
var event2 Event
err = json. Unmarshal(b, & event2)
if err != nil {
return err
}
fmt. Println(event1. Time)
fmt. Println(event2. Time)
// 输出结果
// 2021 - 01 - 10 17 :13 :08.852061 + 0100 CET m=+ 0.000338660
// 2021 - 01 - 10 17 :13 :08.852061 + 0100 CET
可以看到event2的时间比event1少了单调时钟。因此也不能直接event1 == event2来判断两个时间是否相等。可以使用event1.Time.Equal(event2.Time)来比较。另一种处理方法则是在event1定义时调用t.Truncate(0)将单调时间剥离,这样就可以用==来比较了。
map of any
当把json解析到 map[string]any 类型,会出现数字类型解析错误的情况。解决方法可以使用 json.Decoder 来代替 json.Unmarshal 方法。
延伸阅读go json 实践中遇到的坑
78. Common SQL mistakes
Forgetting that sql.Open doesn’t necessarily establish connections to a database
sql.Open 可能只是验证其参数而不创建与数据库的连接,如果要检测与数据库的连接,得调用ping。
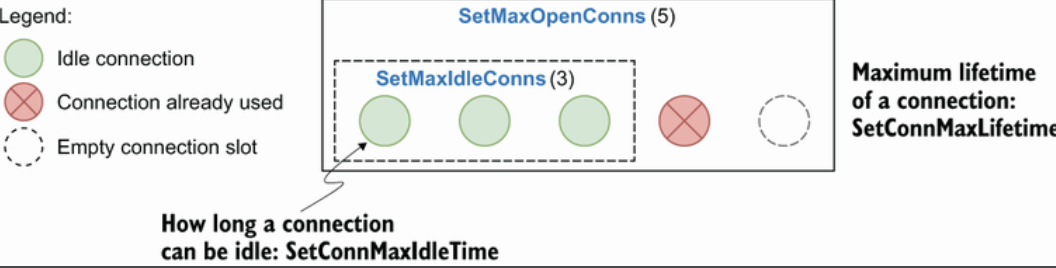
Forgetting about connections pooling
sql.Open 返回一个sql.DB结构。这个结构不表示单个数据库连接,而是表示连接池。
一些参数解释
SetMaxOpenConns:最大连接数,默认无限。应该设置到一个合理值以确保它符合底层数据库可以处理的情况
SetMaxIdleConns: 最大空闲连接数,默认2。如果应用有大量的并发请求应该加大一些,否则应用程序可能会遇到频繁的重新连接。
SetConnMaxIdleTime:一个连接在被关闭之前可以空闲的最大时间,默认无限。需要设置为一个合理值,当应用属于有突发流量类型,有时候需要创建大量连接,而大部分时候属于低流量时要确保创建的连接最终被释放。
SetConnMaxLifetime:一个连接在被关闭之前可以保持开放的最大时间。为了使得数据库负载均衡,需要设置一个合理值,使应用程序永远不会使用一个连接太长时间。
Not using prepared statements
Mishandling null values
对于一个可能为空的字段,最好使用指针或者sql.Nullxxx来处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
rows, err := db. Query("SELECT DEP, AGE FROM EMP WHERE ID = ?" , id) ❶
if err != nil {
return err
}
// Defer closing rows
var (
department string
age int
)
for rows. Next() {
err := rows. Scan(& department, & age) ❷
if err != nil {
return err
}
// ...
}
// 当 department为空时,会得到错误: sql: Scan error on column index 0 , name "DEPARTMENT" :
converting NULL to string is unsupported
// 解决方法一
department * string // 定义为指针
// 解决方法二
department sql. NullString // 定义为 sql. NullString
Not handling row iteration errors
for rows .Next() {} 循环可能会因为没有查询到值或者遇到错误退出,退出后要调用 rows.Err() 看是否是正常退出。
79. Not closing transient resources
HTTP body
要记得调用resp.Body.Close()关闭body,否则GC不会主动回收内存和描述符,可能会导致TCP被占满。不过如果没有读body,那默认的 http transport 会直接关闭连接。
在高并发场景下,如果要使用长连接,可以使用io.Copy(io.Discard, resp.Body) 读取Body的内容。
sql.Rows
前面说了sql库会维护一个连接池,只有及时rows.Close才会把连接放回链接池。
os.File
写文件操作是异步的,对写入的文件进行close操作,可能会遇到在buffer内的数据没有完全刷到磁盘的错误,所以在close的时候如果遇到错误要处理。
不过可以调用Sync来将数据刷入磁盘,这时候可以忽略Close的错误。
80. Forgetting the return statement after replying to an HTTP request
1
2
3
4
5
6
7
8
9
unc handler(w http.ResponseWriter, req *http.Request) {
err := foo(req)
if err != nil {
http.Error(w, "foo", http.StatusInternalServerError)
return // 这个return至关重要,因为虽然给客户端返回了500,但是handler还是会继续执行。
}
// ...
}
81. Using the default HTTP client and server
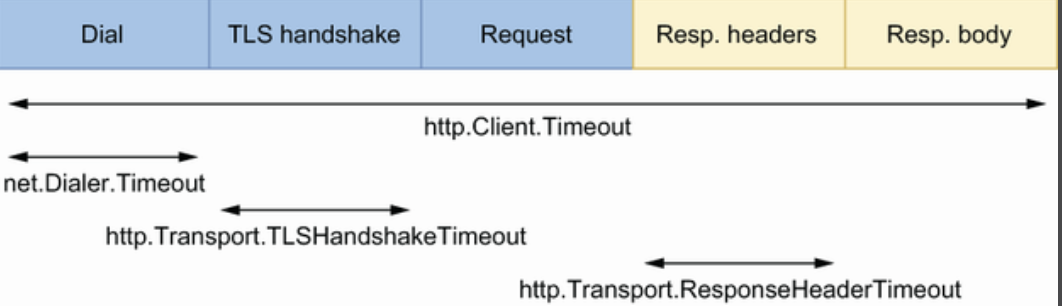
client
直接使用标准库的里的client和server可能会存在问题,因为他们没有合理的配置项,比如使用 http.Client 发送请求,没有配置超时可能会带来问题。下图是一个http请求的几个步骤和时间消耗。
上图种几个超时时间的配置方法
1
2
3
4
5
6
7
8
9
10
lient := &http.Client{
Timeout: 5 * time.Second, // 全局的超时时间
Transport: &http.Transport{
DialContext: (&net.Dialer{
Timeout: time.Second, // Dial的超时时间
}).DialContext,
TLSHandshakeTimeout: time.Second, // TLS握手的超时时间
ResponseHeaderTimeout: time.Second, // 读取header的超时时间
},
}
关于默认HTTP Client 还要知道它是如何处理连接的。
默认情况下,HTTP Client 会维持一个连接池。客户端在请求的时候可以重用连接(也可以通过设置 http.Transport.DisableKeepAlives 为 true 来禁用)。
有一个额外的超时来指定空闲连接在连接池中保留多长时间:http.Transfer.IdleConnTimeout默认值为90s,意味着这个连接在90s内都能给其他请求复用。
http.Transport.MaxIdleConns 用于配置连接池的最大数量,默认为100。http.Transport.MaxIdleConnsPerHost 用于限制每个host的连接池数量,默认为2,表示如果我们对同一个host触发100次请求,只用2个请求保留在连接池中,如果我们再触发100次请求,那么我们还要再重新创建98次新的连接,这个配置对请求响应的影响也极大。
server
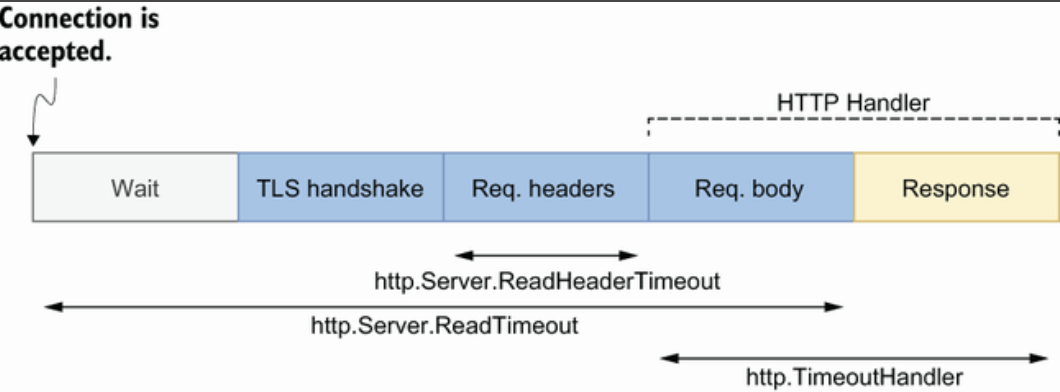
服务端配置超时是为了保护自己的资源不被消耗殆尽。一个http server接收请求的步骤和的时间消耗
服务端设置长连接的方法是配置长连接的最长超时时间 IdleTimeout , 如果 http.Server.IdleTimeout 没有配置就会和 http.Server.ReadTimeout 保持一致,会在结束请求后就立马结束连接。
第十一章
82. Not categorizing tests
1
2
3
4
5
6
7
func TestInsert(t * testing. T) {
if os. Getenv("INTEGRATION" ) != "true" {
t. Skip("skipping integration test" )
}
// ...
}
1
2
3
4
5
6
func TestLongRunning(t * testing. T) {
if testing. Short() { ❶
t. Skip("skipping long-running test" )
}
// ...
}
83. Not enabling the -race flag
对于有并发处理的代码,建议开启-race来测试,可以检测出数据竞争。不过启用时对内存和性能有很大的影响,所以必须在特定的条件下使用,如本地测试或CI。
84. Not using test execution modes
85. Not using table-driven tests
建议使用表驱动来实现测试用例,goland生成的test默认就是table-driven
86. Sleeping in unit tests
87. Not dealing with the time API efficiently
一些依赖time.Now()获取时间的测试,没有考虑函数本身的执行时间或者其他请求的时间导致得不到预期结果。
88. Not using testing utility packages
89. Writing inaccurate benchmarks
Not resetting or pausing the timer
1
2
3
4
5
6
7
func BenchmarkFoo(b * testing. B) {
expensiveSetup() // 测试之前需要做一些 setup工作消耗一些时间
b. ResetTimer() // 在真正性能测试之前先 resettime
for i := 0 ; i < b. N; i++ {
functionUnderTest()
}
}
1
2
3
4
5
6
7
8
func BenchmarkFoo(b * testing. B) {
for i := 0 ; i < b. N; i++ {
b. StopTimer() // 先停止计时
expensiveSetup()
b. StartTimer() // 处理完再开启重新计时
functionUnderTest()
}
}
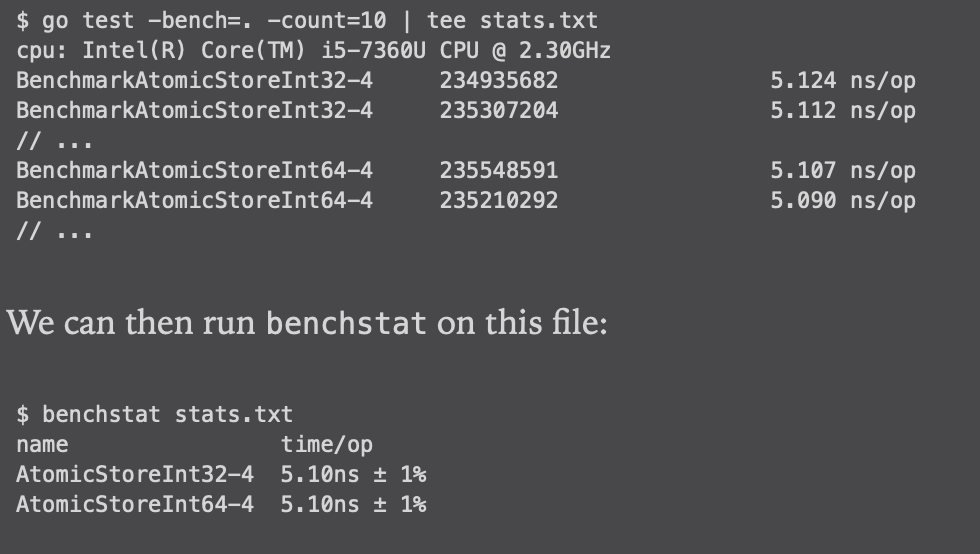
Making wrong assumptions about micro-benchmarks
micro-benchmarks最好多运行几次,只执行一次可能会得到错误的结论。利用count执行多次将结果重定向到文件中,然后采用benchstat来计算均值
Not being careful about compiler optimizations
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
func popcnt(x uint64) uint64 {
x -= (x >> 1 ) & m1
x = (x & m2) + ((x >> 2 ) & m2)
x = (x + (x >> 4 )) & m4
return (x * h01) >> 56
}
// 原始函数
func BenchmarkPopcnt1(b * testing. B) {
for i := 0 ; i < b. N; i++ {
popcnt(uint64(i)) // 内联优化会影响到这行代码
}
}
// 优化后的函数
func BenchmarkPopcnt1(b * testing. B) {
for i := 0 ; i < b. N; i++ {
// Empty // 直接使用函数主体代替了函数调用
}
}
可以通过以下方式避免被优化,当然更合理的方式一是加上-gcfloags="-l",-l 表示禁止内联优化。另外也可以在代码中加上//go:noinline避免被优化。
1
2
3
4
5
6
7
8
9
var global uint64
func BenchmarkPopcnt2(b * testing. B) {
var v uint64
for i := 0 ; i < b. N; i++ {
v = popcnt(uint64(i)) // 加上一个赋值,避免被优化
}
global = v
}
Being fooled by the observer effect
90. Not exploring all the Go testing features
使用go test -coverprofile=coverage.out 来查看覆盖率
测试文件可以和实现代码放在同一个包中,测试文件也可以放在_test包中
使用Setup 和 teardown 初始化和清理环境。
可以调用 t.Cleanup 注册一个闭包函数做清理工作,在测试结束后清理环境。
第十二章 Optimizations
91. Not understanding CPU caches
92. Writing concurrent code that leads to false sharing
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
type Input struct {
a int64
b int64
}
type Result struct {
sumA int64
sumB int64
}
func count(inputs []Input ) Result {
wg := sync. WaitGroup{}
wg. Add(2 )
result := Result{}
go func () {
for i := 0 ; i < len(inputs); i++ {
result. sumA += inputs[i]. a
}
wg. Done()
}()
go func () {
for i := 0 ; i < len(inputs); i++ {
result. sumB += inputs[i]. b
}
wg. Done()
}()
wg. Wait
上面的代码是用两个goroutine分别将一个struct中两个数组进行累加,并将结果赋值给另一个struct的两个字段。按照理解,都是独立的内存,不会出现同步写。
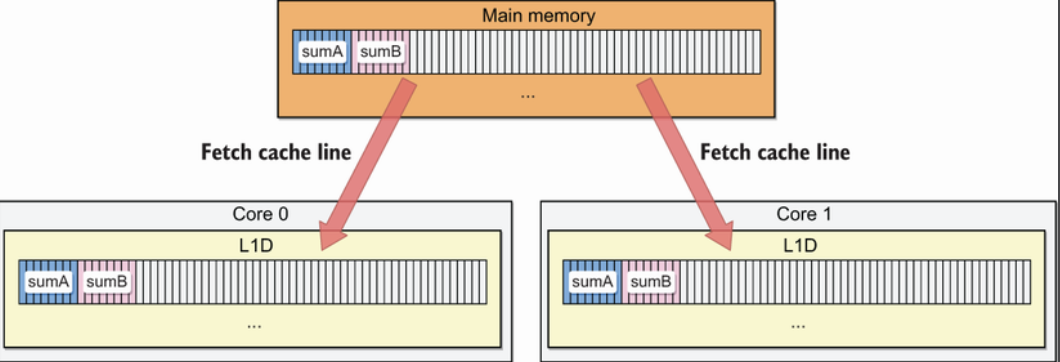
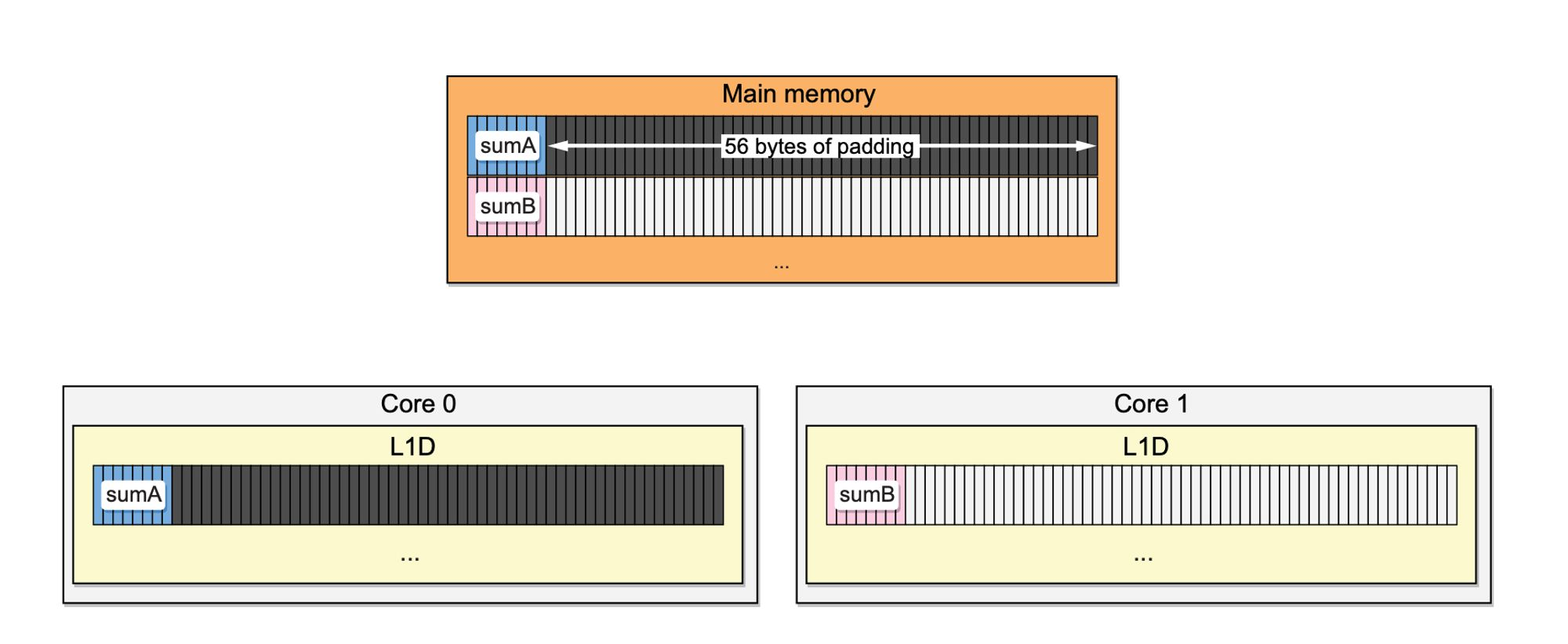
在内存中,因为每个cache line是64字节,所以sumA和sumB在同一个内存块,假设每个goroutine都在独立的CPU上运算,L1D会加载同一行内存到Cache Line中,CPU运算时候也是先写回到Cache Line中,所以每个CPU在运算时候为了保证内存一致性,在写入时是使用同步写的模式。
解决办法就是把sumA和sumB分到两个不同的cache line中可以明显提高性能。
1
2
3
4
5
type Result struct {
sumA int64
_ [56]byte // 增加56字节是为了确保sumB可以到另一个cache line
sumB int64
}
必须记住,跨goroutine共享内存在最低的内存水平上是一种假象。当至少有一个goroutine是写程序的时候,一个cache line在两个核之间共享,就会出现假共享。如果我们需要优化一个依赖并发的应用程序,我们应该检查假共享是否适用,因为这种模式已知会降低应用程序的性能。我们可以通过填充或通信来防止虚假共享。
93. Not taking into account instruction-level parallelism
94. Not being aware of data alignment
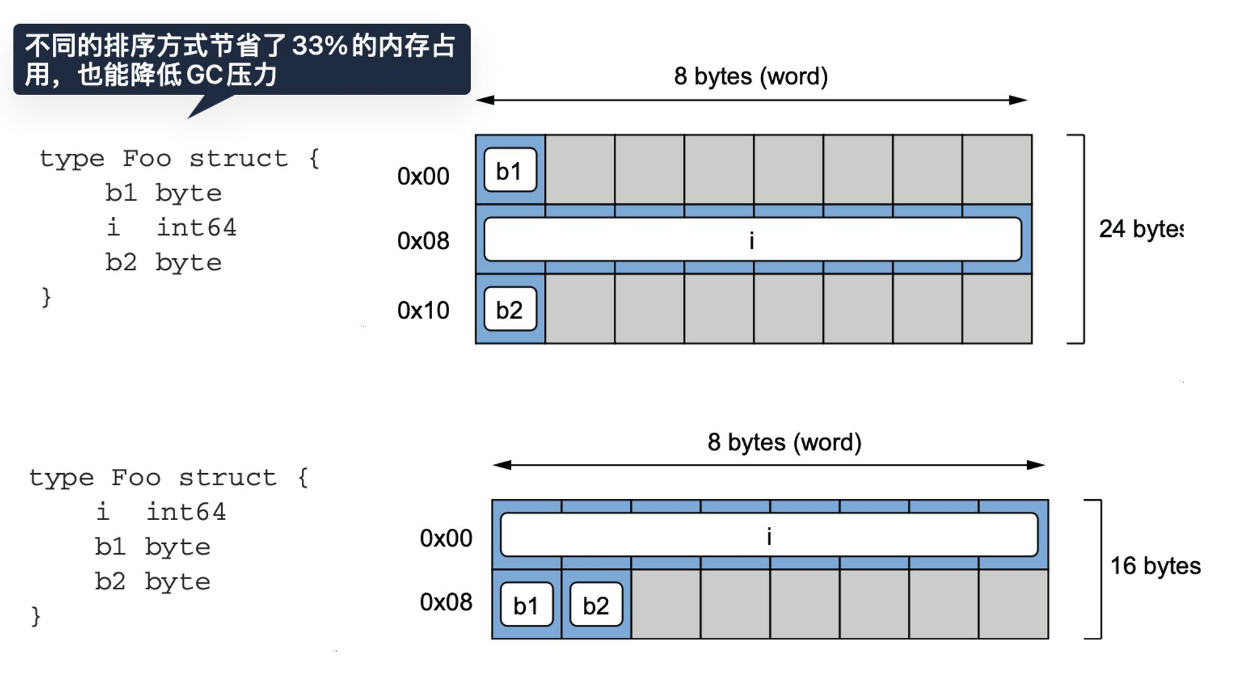
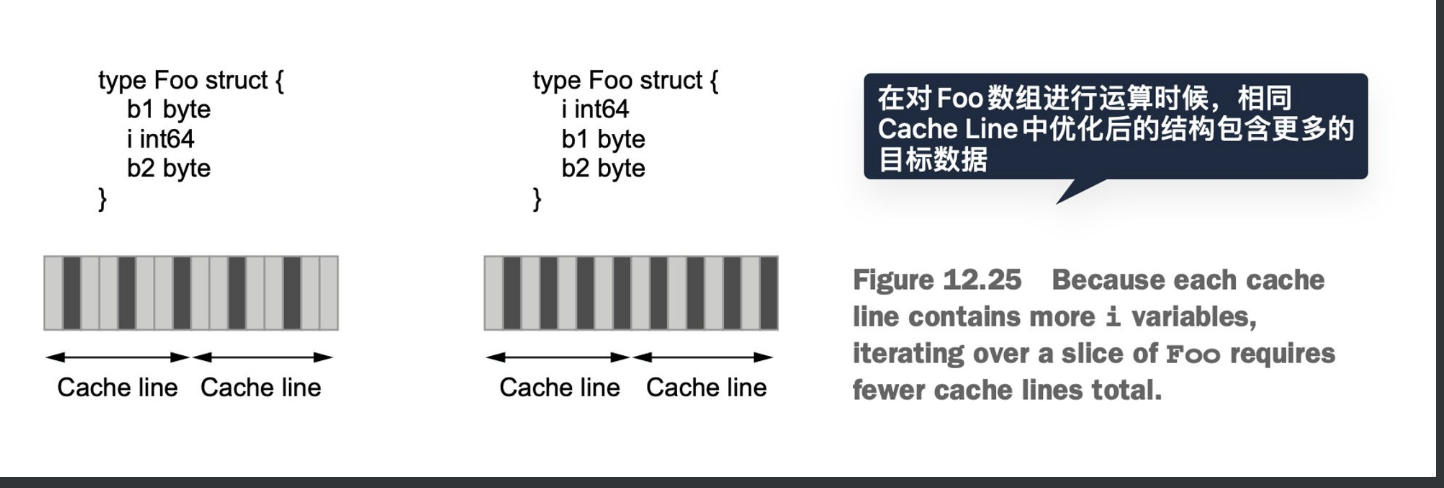
关于内存对齐,struct中不同的顺序占用的内存也不一样
除了优化内存也能优化计算速度,因为压缩存储以后每个cache line会有更多数据,带来更高的缓存命中率
95. Not understanding stack vs. heap
go逃逸分析,网上很多分析文章。文中总结一些逃逸的变量
全局变量,因为所有goroutine可以访问它们
发送到channel的指针
被发送到通道的指针引用的变量
如果局部变量太大而无法放入栈
如果局部变量的大小未知。例如,s := make([]int, 10) 不会逃逸到堆,但s := make([]int, n) 会,因为它的大小基于一个变量
如果slice的底层数据因为调用append被重新分配
函数的形参是any类型,那么形参也会逃逸
96. Not knowing how to reduce allocations
减少内存分配的一些思路
使用strings.Builder来代替+来拼接字符串
避免不必要的string和[]byte转换,尽量使用原生函数
slice和map预先分配内存,减少底层扩容
可以使用sync.Pool来复用内存
97. Not relying on inlining
99. Not understanding how the GC works
100. Not understanding the impacts of running Go in Docker and Kubernetes
主要提到要注意如果k8s运行的环境不是安全容器,进程读到的全局CPU核数和宿主机一致,会导致错误配置了GOMAXPROCS的值和宿主机一样,GO默认开启的协程个数就会远超容器实际运行环境提供的CPU个数,导致协程频繁的调度切换程序运行时间被拖慢。建议使用 automaxprocs 包来配置GOMAXPROCS。
第二章 Code and project organizatiion
第三章 Data Types
27. Inefficient map initialization
第四章 Control structures
第五章 Strings
第六章 Function and methods
第七章 Error management
第八章 Concurrency: Foundations
第九章 Concurrency: Practice
第十章 标准库
第十一章
第十二章 Optimizations

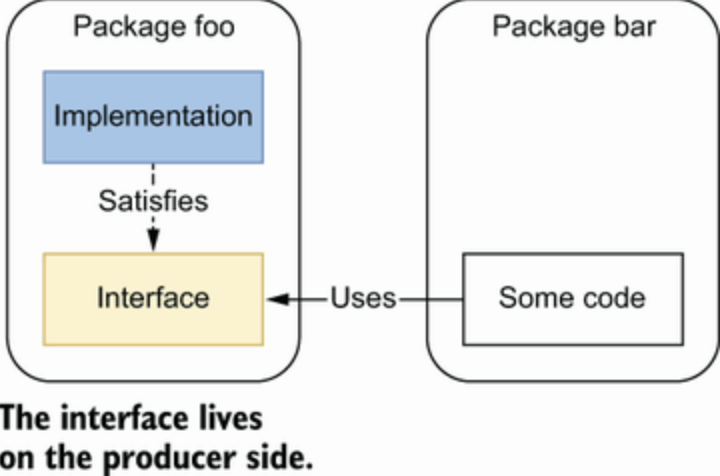
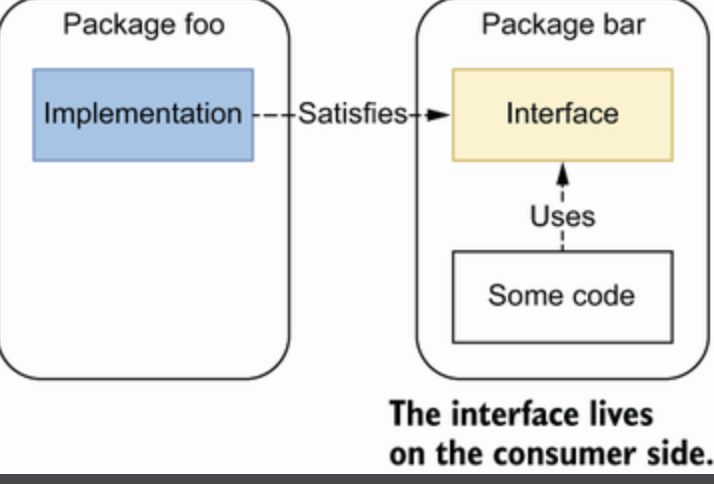 作者建议应该采用消费者模式,即接口在使用端定义,可以更好地满足里氏替换原则。
作者建议应该采用消费者模式,即接口在使用端定义,可以更好地满足里氏替换原则。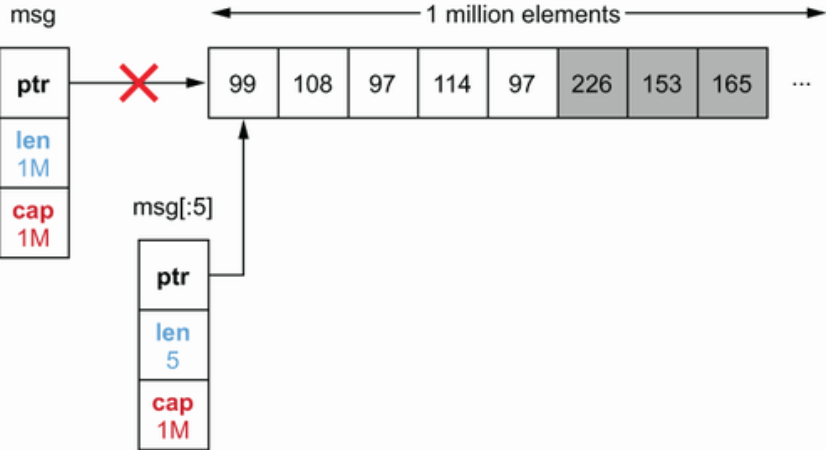 上面的代码,如果
上面的代码,如果