go 1.14.1 timer bug
go 1.14.1 的timer 包存在bug,会导致服务hang死,问题发生在两年前,而go目前的版本也已经迭代到1.22,还是整理出来以记录当时定位问题的思路。
问题描述
有个服务在压测时发现多容器压测,每次必有一台容器出现CPU跑满的现象。
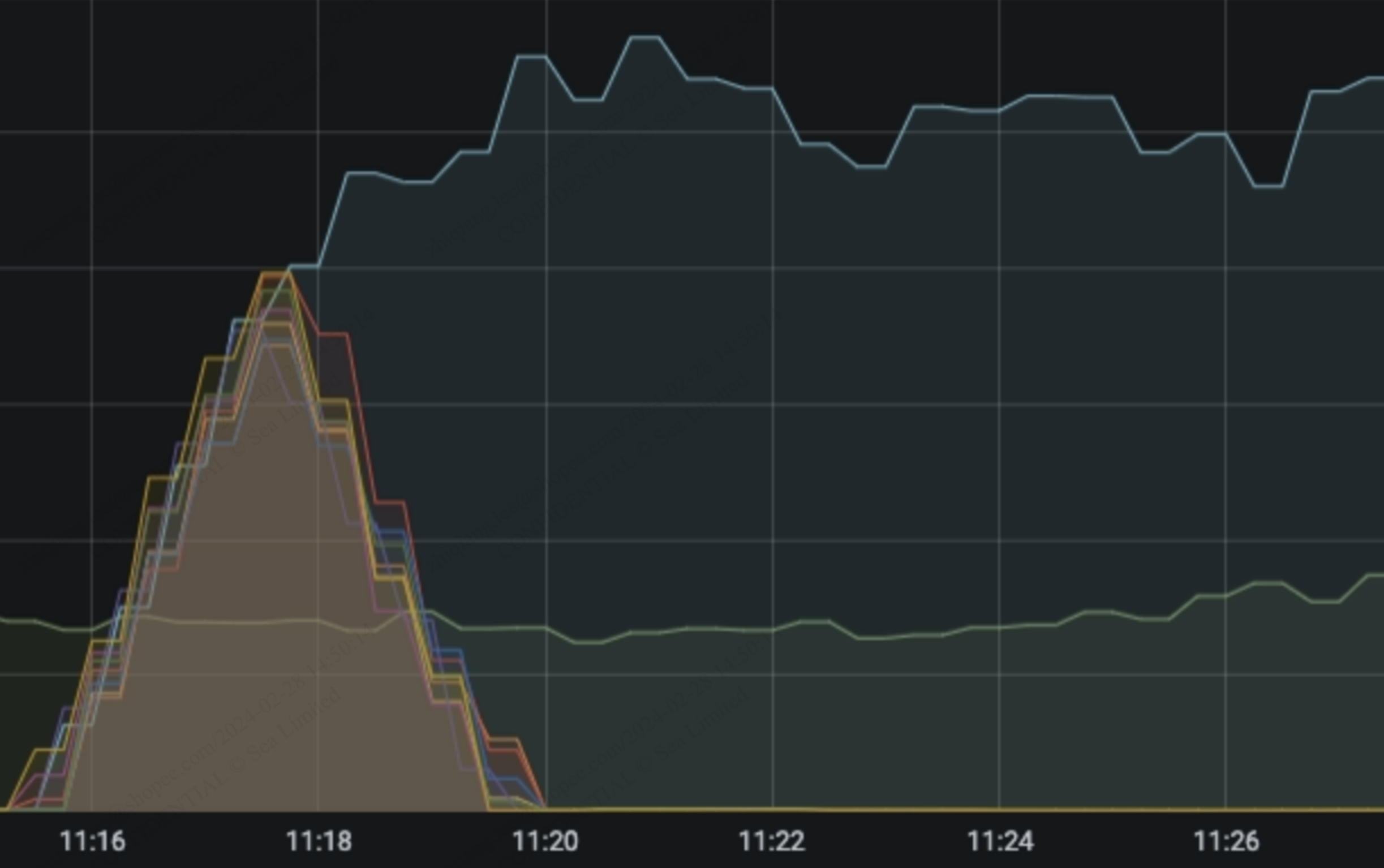
定位
尝试进入该容器使用 pprof 抓火焰图进行分析,但进入容器后却发现 pprof 监听的端口根本连不上,只能另想办法。使用 delve 来试试。
首先执行 top 找到 cpu 跑满的线程。
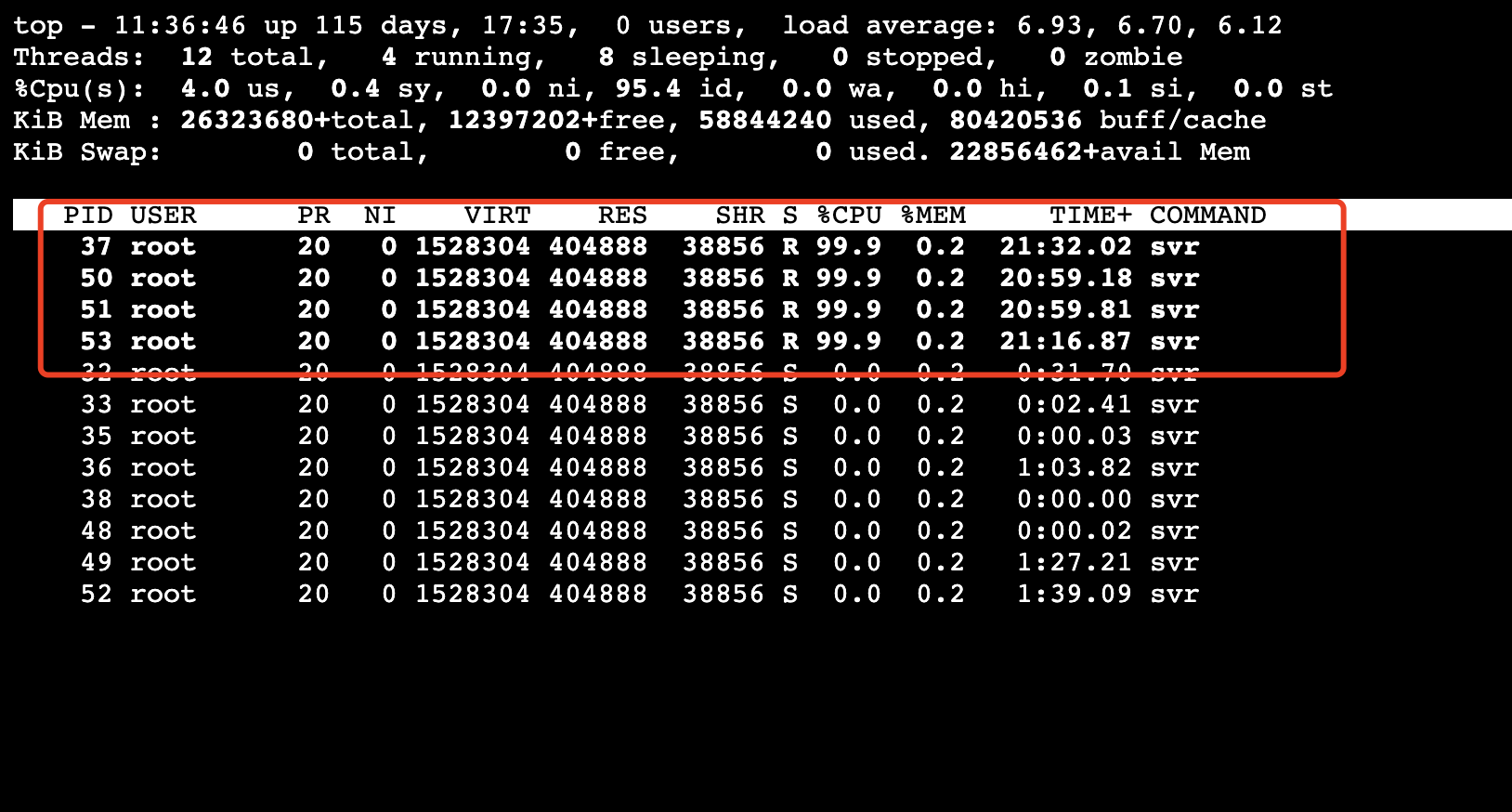
容器设置是4 core,这里看到也是前面4个线程占满了所有CPU。
接着执行 dlv attach <PID> 进入线程,看到以下信息
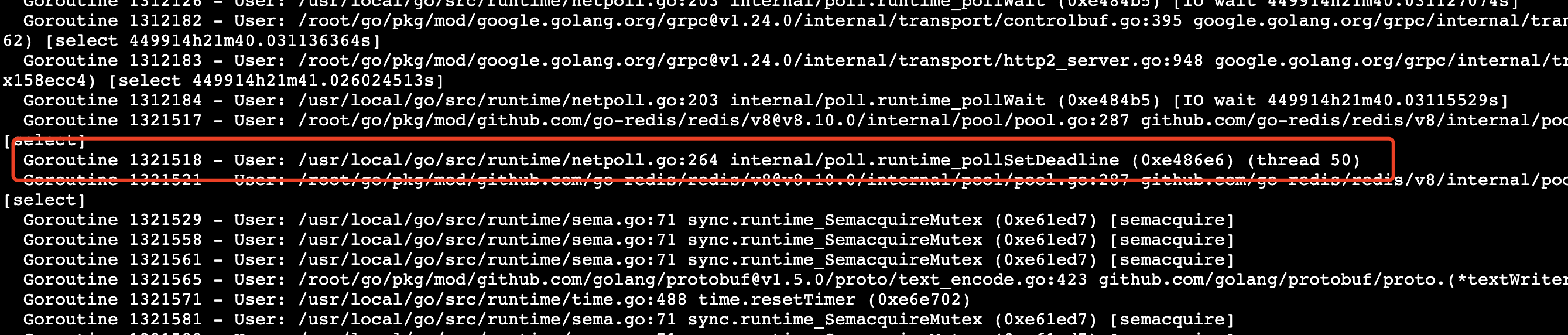
这里看到看起来与redis相关,刚好这次修改有一处redis连接处的变更,猜测与此有关于是回退这个变更再次压测,很遗憾,很快问题又出现了。 继续进入上图中的goroutine,看到下图
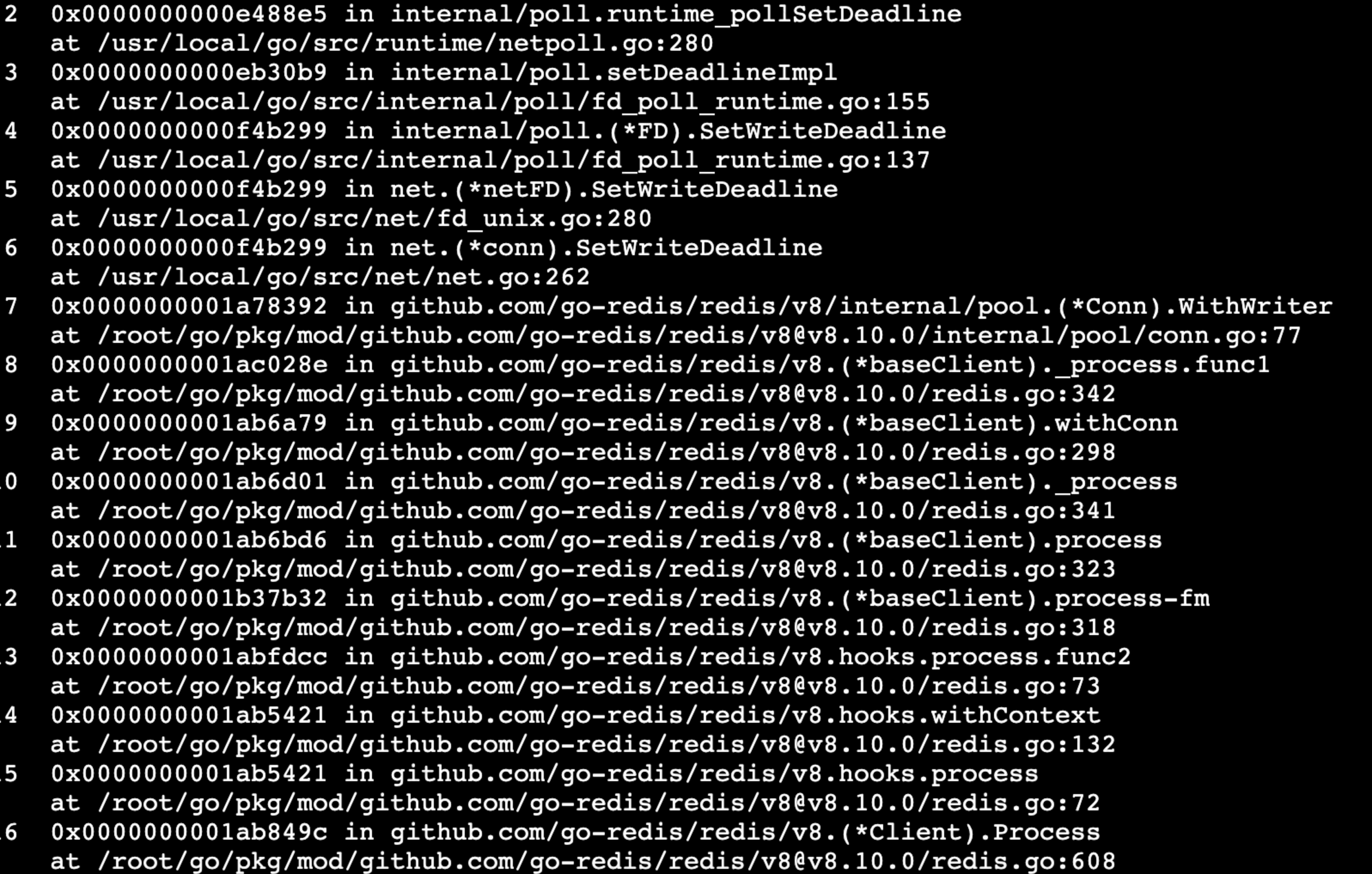
这里漏了一个关键的堆栈,因为总结时现场已经破坏,正是通过这个堆栈在github找到这个issue,堆栈内容与issue中描述相同,可以参考issue。
为了验证是否因为这个timer 的bug导致,将go升级为14.2,再次压测,问题没有重现,基本上可以确定解决。
原因分析
简单来说就是
- go 1.14对timer重新设计,将timer挂在P上的一个小根堆上,每一次调度会去查看是否有到期的timer,即调用runtimer这个方法,如果有则执行。
- 另外timer中还有一个状态机,如果要修改timer的状态会先将状态置为modifying状态。在runtimer这个函数中如果状态为modifying会调用runtime.osyield() 自旋等待,直到timer的modifying状态解除。
- 而modifying状态正是这个线程自己设置的,所以永远都等不到了,进入死锁。
如何解决
对于我们服务来说,直接升级go版本即可,现在我们团队在选择go版本的时候有一个原则,Golang社区发布的倒数第二个大版本的最后一个小版本。 比如当前已发布go 1.22.x,那么应该选择1.21.7。
go 社区解决方案在这个issue中说得很清楚。从修复diff来看,在修改timer状态的时候加了一个锁。