内存一直涨,是内存泄露吗?
问题
SRE 反馈一个服务内存异常一直涨下不去,8G 内存的容器已经去到90%,怀疑是内存泄漏。
如下图,在定位解决之前,只能通过重启大法缓解。但可以看到服务重启以后内存会快速增长,然后半夜因为业务流量小趋于平稳,而到了白天用户流量上来又开始快速增长。
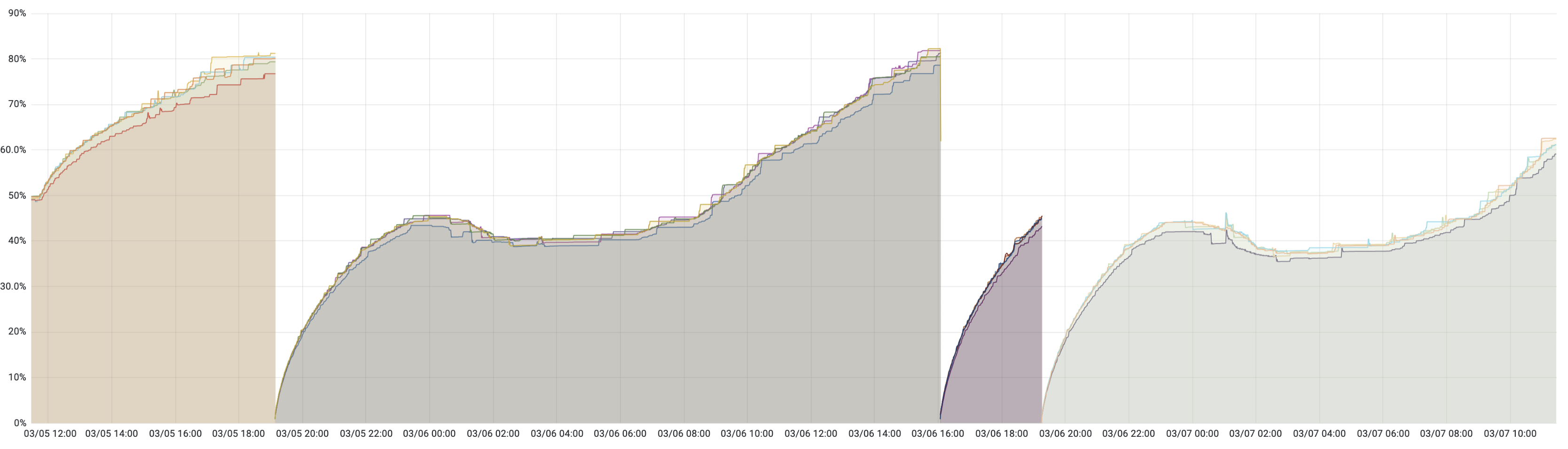
咋一看,严重怀疑内存泄漏。但也奇怪,这个服务运行了近4年,也只是第二次出现这种情况。
定位
首先对比 CPU / goroutine / TCP 连接数的指标,均很平稳,确定只是内存问题。
对于 go 程序,接下来显然第一时间采用 pprof 进行内存采样,但由于当时内存使用率已经太高采样失败,只能重启以后进行采样,第一次抓到 GetActivateChanceEntry 这个函数用了 20 M 内存。
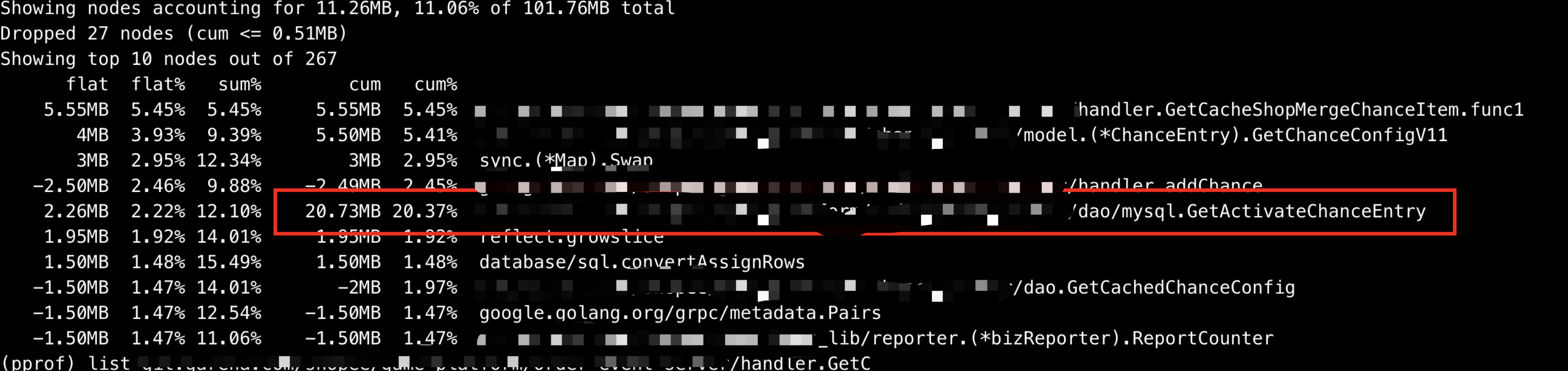
使用 list 命令进去这个函数看到在调用 GetChanceEntry 这个函数使用了 13 M 内存
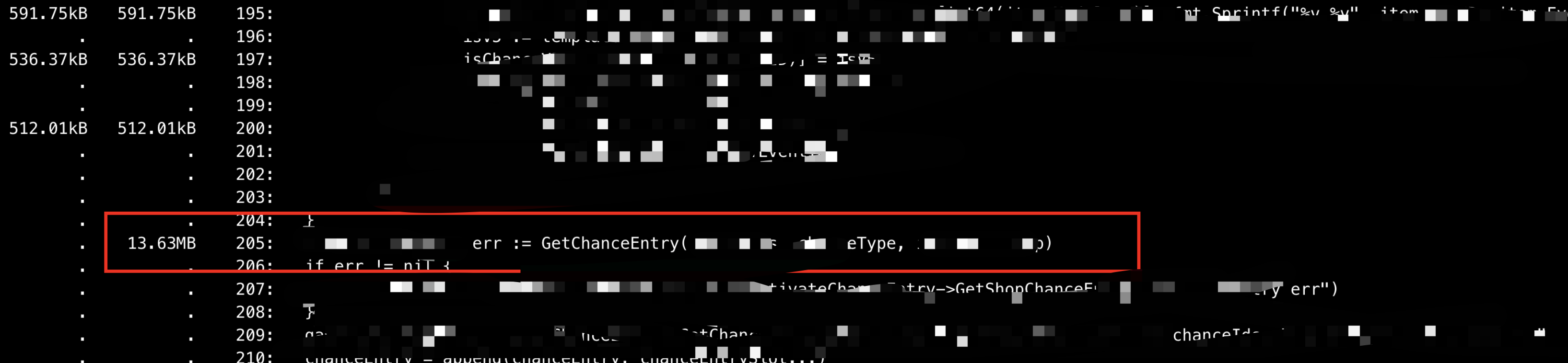
这个 GetChanceEntry 内部逻辑只是查 DB,对 DB 返回数据中的 json 字段进行反序列化,处理以后再序列化。 猜测会不会是一次性查询的数据太多?数据量是根据查询条件决定,会不会是查询的条件不合理?
|
|
因为日志没有把 SQL 打印出来也不知道每次查询的数据量会多大,在容器中抓了一段时间和 MySQL 之间的数据包,确实也有大包。
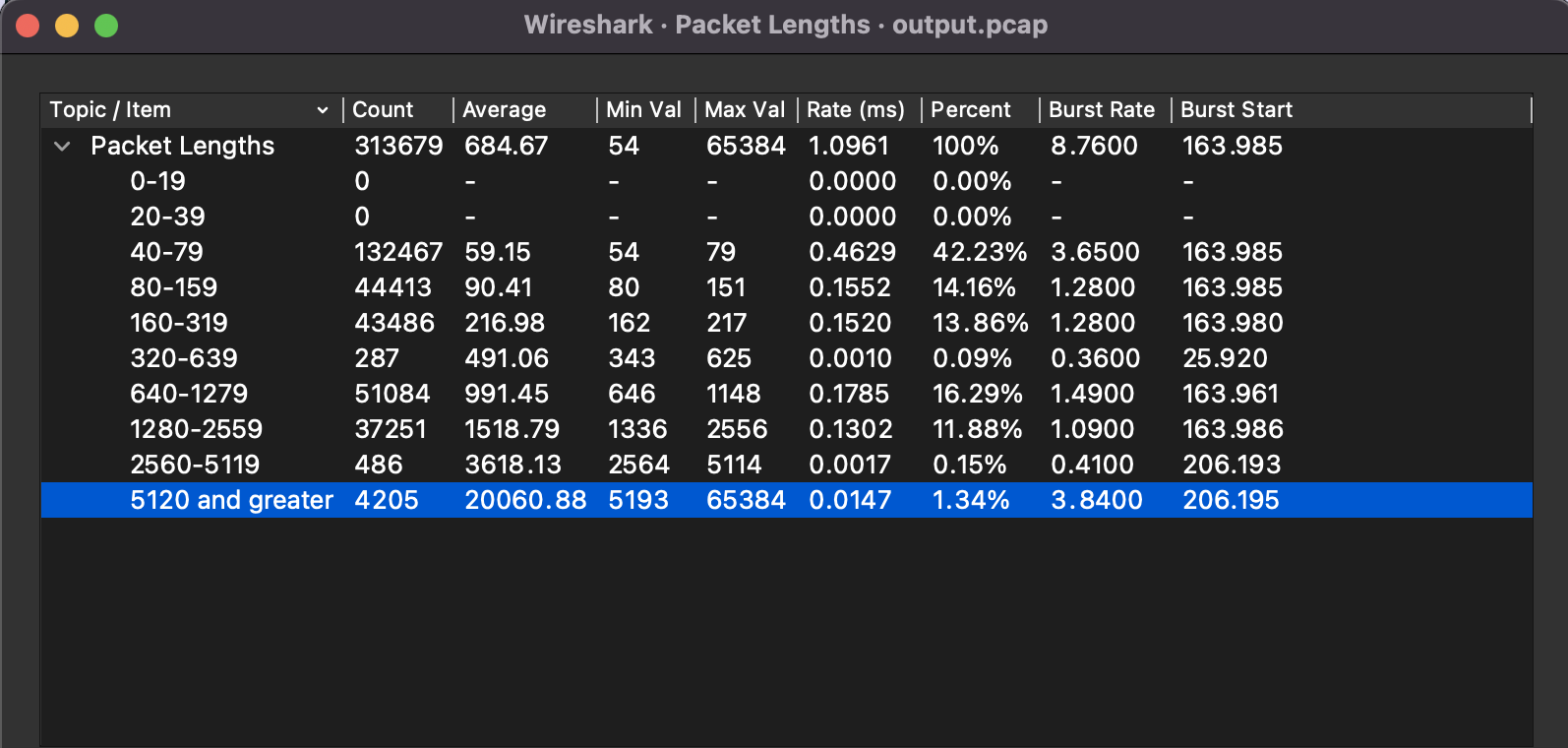
后来从其他地方的日志中查到这个 id IN 条件中最大有 3181 个 id ,这是来自一个 local cache 的每分钟定时刷新(两次调用)。加上这几千条数据确实不小还需要 json 序列化反序列化,猜测会不会是这里导致了内存泄漏,每分钟申请一块几十 M 的内存。于是将这个 cache 的刷新时间延长至 5 分钟,减少调用次数。但很遗憾,发上去以后表现和修改前一致。增长速率依然很快。怕半夜OOM,在下班前再次实行重启大法一次。
再次定位
上一次发版以后,虽然没解决问题,但也不是完全没用,由于 GetChanceEntry 的调用频率确实降低了,采样的时候便更快发现了另一处高耗内存的地方。
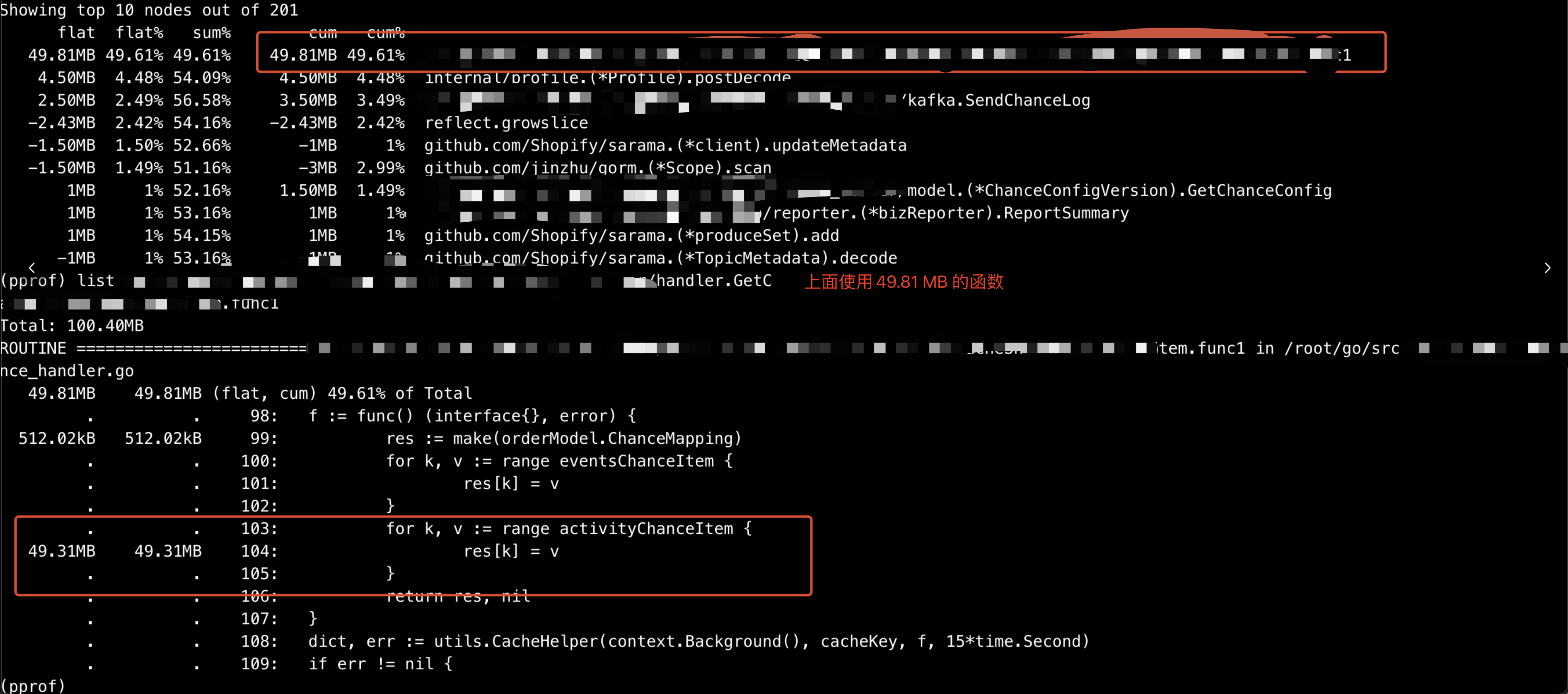
这一次采样 40 s , 可以看到图中 top 1 这个函数的内存消耗可以说是遥遥领先,这个函数的作用是为每个用户 id 创建一个 local cache,代码如下。CacheHelper 中用的是 go-cache 。 list 进去发现第二个循环使用了绝大部分内存,看到这里,大概知道原因了,因为这个 id 的量非常大,每次请求的重复率非常低,因此 local cache 的量自然就高了。
验证
为了更好验证这个问题,在本地写了一个 test 来进行对比
|
|
在这个测试中,发现这里占用的内存确实比较多,模拟 100k 个id
|
|
可以看到,内存直接去到 1G +。而线上有几十万 id 占好几 G 内存也是合理的,所以基本确定并没有内存泄漏,而是这个 local cache 消耗内存过大。
解决
要解决这个问题,首先就是优化这个内存,发现其中 local cache 中的 value 数据定义如下
|
|
将 idData 修改为指针再次运行上面的 test
type dataMapping map[string]*idData
这一次有了很明显的改善
|
|
可以看到,只消耗了 331 M ,比起 1 G 来说还是小了很多。
再从业务代码逻辑来看,发现这里的缓存只是存储了一个内存计算的内容,这个计算也就是几十次的一个循环,从内存中汇总数据存储,理论上这种 O(1) 的计算和做一次 local cache 的性能差异并不能感知到,而且这是异步消费任务可以忽略不计。
以时间换空间,可以直接移除这个 local cache 即可。
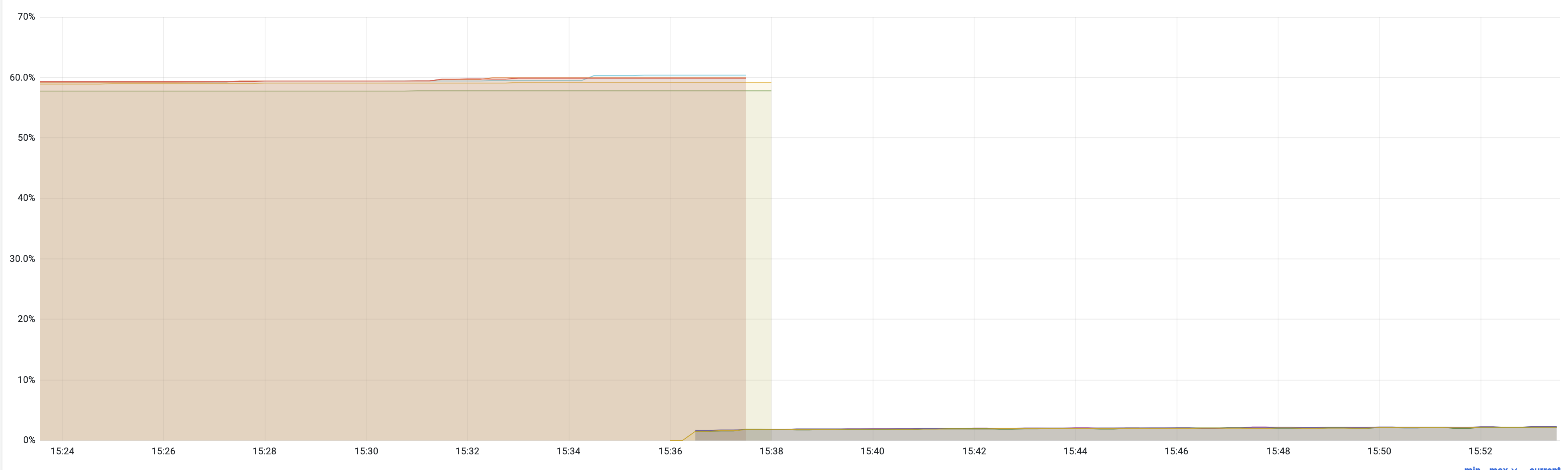
最后上线以后,可以看到内存持续在 1% 的使用率。
总结
总体来说,定位过程走了一些弯路,主要还是一开始就先假设问题是内存泄漏,拿着锤子找钉子。实际上看到的几处内存使用多的地方实际都是正常的开销,最终花了不少时间。从这个定位这个问题的过程中,对于 local cache 的使用有几点思考,在以后的开发中需要注意。
- 用户向数据做缓存需要先考虑是否有必要,如果一定需要再权衡数据量再决定是存本地还是分布式缓存中。
- 本地缓存的数据尽量存指针而不是对象。
- 另外一个之前曾经多次遇到的问题,本地缓存的数据应该只读,如果要修改,则建议进行深拷贝后再修改,避免隐藏的竞争问题。
还有一点感受,pprof 是通过采用获取系统数据,因此定位问题时尽量多抓取几次进行对比,以更准确定位到问题。